There are many things I'm thankful for this year. Perhaps most notably, the new year marks the halfway point of my 3-year stint as "Area Dean for Computer Science". Not that I'm counting. I'm very thankful for that.
Strangely, though, despite the additional job, looking back on the year, it's been very enjoyable, research-wise. That's not due to me. So, importantly, it's time to thank some people.
First off, I thank my students. Justin, Zhenming, and (now-ex-student-but-collaborator-who-I-still-call-student) Giorgos are all doing really interesting and exciting things. They've been teaching me all sorts of new stuff, and have put up with my increasingly random availability as various non-essential Area Dean type meetings jump in the way. Having multiple students all making great progress on entirely different areas makes the job really, really fun.
Thanks to Michael Goodrich, who called me up about two years ago (has it been that long? I had to go back and check) and wondered if I could help him on a project where he wanted to use cuckoo hashing. And since then, he's continued to keep me busy research-wise, as we've jumped from trying to understand how to use cuckoo hashing in Oblivious RAM simulations to other practical uses of cuckoo hashing as well as other algorithmic and data structures problems. He's an idea factory, and I get to come along for the ride.
Similar thanks to George Varghese, who regularly provokes me into networking research. I always have to listen closely when talking to George because there's usually some insight he has, often I think not yet fully formed in his own mind yet, that when you see it will leave you with an AHA moment. (Sometimes, then, George mistakenly attributes the idea to me, even though my understanding comes from listening to him.) Also, both Michael and George have been really, really patient with me this year.
I of course thank the MIC/MINE group, who I've already been thanking all week. And John Byers, who has worked with me on more papers than anyone now, and is still willing to keep coming back.
I'd like to thank all the CS faculty at Harvard. When I travel around, and people ask me if it's hard being Area Dean, and how much do I have to do, I have to explain that it's not really that hard. There's some basic handling of paperwork and e-mail. Other than that, as a group we have lunch on Fridays to talk about things we have to do. I then sometimes have to ask people to do things so things actually get done (because I can't do everything myself). Then people do them, and as a group we're all very happy. When I try to explain this, sometimes other people look at me like I'm totally insane, which I've come to interpret as meaning that this is not the way it works everywhere. I've got a great group of colleagues, so I can still sneak in some research time here and there.
I also tremendously thank Tristen Dixey, the Area Administrator for CS and EE. She's the one that actually runs the place (thank goodness). Seriously, I'd be lost without Tristen. Many are the requests sent to me where my response is, "Let me check with Tristen on that." Because she knows what to do.
Thanks to all my other co-authors, and anyone else I'm forgetting to thank.
Finally, I thank the NSF, as well as currently Google and Yahoo, for sponsoring my research. I especially have to thank the NSF; while I can't say I think they're perfect, I can say that I think they're wonderful. They've funded me as a faculty member for over a decade now, and my students and I couldn't do the research I like to do without them.
I also, more privately, thank my family, for putting up with my working habits.
Happy new year to all.
(Just 18 more months...)
Friday, December 30, 2011
Thursday, December 29, 2011
Cross-Cultural Learning Curve: Sending a Paper to Science
We decided to submit our paper on MIC and MINE to Science it's a venue that my co-authors were familiar with and very interested in applying to. I was happy to go along. Moreover, it seemed like the right venue, as we wanted to reach a large audience of people who might be able to use the approach.
Sending a paper into Science feels very different than sending to a FOCS/STOC/SODA or SIGCOMM conference, or to a CS journal. I think there are many reasons for this. (And I'm trying not to offer judgment, one way or another -- but rather to describe the experience.)
1. There's a feeling that there's not really a second shot. If you submit a paper to a major CS conference, and it doesn't get in, you revise as needed and can try for the next one. (Some papers get submitted 3, 4, or more times before getting in.) For a journal like Science, they'll only review a small fraction of submitted papers, and if your paper doesn't make it in, you're not going to get a second shot there; you'll have to find another, arguably less desirable venue. (SIGCOMM can feel more that way, more than FOCS/STOC, but definitely not to the same extreme.)
2. Perhaps correspondingly, there's a greater focus on polish of the final form before submission. The article should be ready for publication in the journal, which has a high standard in terms of the appearance of the articles, so there's a sense that it should look good. This means much more time is spent on writing (and re-writing, and re-writing), on trying to figure what the perfect graphic is, on making that graphic look awesome, and other aspects of the presentation. On the whole, CS papers are, shall we say, much less presentation focused.
3. The paper will (likely) be read by a much broader (and larger) audience. This again changes how one thinks about presentation.
4. For many fields, a Science article is extremely important, much more valued for a student author than even a FOCS/STOC/SIGCOMM paper. (I realize that, in computer science, venues like Science and Nature have not historically been given an especially high importance.)
5. Journals like Science have very strict rules regarding various things. For example, we were not supposed to publish the work in another venue (like a conference) before hand. Once the paper was accepted, there was an "embargo" -- we weren't supposed to talk about it before publication without permission, and we could not announce the paper had been accepted. In CS, we have the arxiv and other online repositories that are used widely by theoreticians; even in areas where double-blind conference submissions are the norm, such rules are not taken anywhere nearly as seriously as by Science, as far as I can tell.
I've also been truly surprised by the amount of reaction the paper has generated. Sure, I had been told that getting a paper in Science is a big deal, but it's another thing to sort of see it in action. (I haven't seen this big a reaction since -- well, since Giorgos, John, and I put the Groupon paper up on the arxiv. But that was very unusual, and this reaction has I think been bigger.) There's definitely a human interest angle that is a part of that -- brothers working together on science makes a more readable news story -- but also there was much more effort behind the scenes. There's the sense that an article in Science is really a big chance to get your work noticed, so you prepare for that as well.
If I had to describe it in one word, I'd say publishing in Science feels much more "intense" than usual CS publications. The competitive aspect -- that some people in CS feel is very important (the "conferences are quality control" argument) and others do not -- feels like it's taken one level up here. Maybe the stakes are bigger. As an outsider, I was both amazed by and bemused by some aspects of the process. Even having been through it, I don't feel qualified to offer a grounded opinion as to which is better for the scientific enterprise, though I certainly feel it's an interesting issue to discuss.
Sending a paper into Science feels very different than sending to a FOCS/STOC/SODA or SIGCOMM conference, or to a CS journal. I think there are many reasons for this. (And I'm trying not to offer judgment, one way or another -- but rather to describe the experience.)
1. There's a feeling that there's not really a second shot. If you submit a paper to a major CS conference, and it doesn't get in, you revise as needed and can try for the next one. (Some papers get submitted 3, 4, or more times before getting in.) For a journal like Science, they'll only review a small fraction of submitted papers, and if your paper doesn't make it in, you're not going to get a second shot there; you'll have to find another, arguably less desirable venue. (SIGCOMM can feel more that way, more than FOCS/STOC, but definitely not to the same extreme.)
2. Perhaps correspondingly, there's a greater focus on polish of the final form before submission. The article should be ready for publication in the journal, which has a high standard in terms of the appearance of the articles, so there's a sense that it should look good. This means much more time is spent on writing (and re-writing, and re-writing), on trying to figure what the perfect graphic is, on making that graphic look awesome, and other aspects of the presentation. On the whole, CS papers are, shall we say, much less presentation focused.
3. The paper will (likely) be read by a much broader (and larger) audience. This again changes how one thinks about presentation.
4. For many fields, a Science article is extremely important, much more valued for a student author than even a FOCS/STOC/SIGCOMM paper. (I realize that, in computer science, venues like Science and Nature have not historically been given an especially high importance.)
5. Journals like Science have very strict rules regarding various things. For example, we were not supposed to publish the work in another venue (like a conference) before hand. Once the paper was accepted, there was an "embargo" -- we weren't supposed to talk about it before publication without permission, and we could not announce the paper had been accepted. In CS, we have the arxiv and other online repositories that are used widely by theoreticians; even in areas where double-blind conference submissions are the norm, such rules are not taken anywhere nearly as seriously as by Science, as far as I can tell.
I've also been truly surprised by the amount of reaction the paper has generated. Sure, I had been told that getting a paper in Science is a big deal, but it's another thing to sort of see it in action. (I haven't seen this big a reaction since -- well, since Giorgos, John, and I put the Groupon paper up on the arxiv. But that was very unusual, and this reaction has I think been bigger.) There's definitely a human interest angle that is a part of that -- brothers working together on science makes a more readable news story -- but also there was much more effort behind the scenes. There's the sense that an article in Science is really a big chance to get your work noticed, so you prepare for that as well.
If I had to describe it in one word, I'd say publishing in Science feels much more "intense" than usual CS publications. The competitive aspect -- that some people in CS feel is very important (the "conferences are quality control" argument) and others do not -- feels like it's taken one level up here. Maybe the stakes are bigger. As an outsider, I was both amazed by and bemused by some aspects of the process. Even having been through it, I don't feel qualified to offer a grounded opinion as to which is better for the scientific enterprise, though I certainly feel it's an interesting issue to discuss.
Tuesday, December 27, 2011
Some of The Fun of Collaborating...The Other People
One of the things I enjoy most about working in algorithms is the breadth of work I get to do. And while I've worked on a variety of things, almost all have been squarely in Computer Science. (If one counts information theory as EE then perhaps not, but CS/EE at the level I work on them are nearly equivalent from my point of view.) But at Harvard there are plenty of opportunities to work with people outside of computer science, and my work on MIC and MINE was my biggest cross-cultural collaboration at Harvard. In particular, the other co-primary-advisor on the work was Pardis Sabeti, who works in systems biology at Harvard -- here's the link to her lab page.
Pardis is no stranger to mathematical thinking -- some of her work that she's most well known for is in designing statistical tests to detect mutations at the very short time scale of humans over the last 10,000 years, with the goal being to identify parts of the genome that have undergone natural selection in response to diseases. So while my take was a bit more CS/math focused (what can we prove? how fast/complex is our algorithm?) and hers what a bit more biology/statistics focused (what is this telling us about the data? what data sets can we apply this too?) the lines were pretty blurry. But it did mean I got to pick up a little biology and public health on the way. Who knew that natural selection could be so readily found in humans? Or that the graph of weight vs. income by country has some really unusual characteristics (weight goes up with national income up to some point, but then goes down again; the outliers are the US, and Pacific island nations)? And that you can find genes that are strongly tied to susceptibility to certain viral diseases?
I must admit, it is a bit intimidating when talking to a colleague about your other projects, and I'm explaining cuckoo hashing and Groupon, while she's discussing flying off for the Nth time this year to Africa for her project on how genes are changing in response to Ebola and Lassa viruses. But it's just encouraged me to keep looking for these sorts of broadening opportunities. Maybe someday I'll find a project I too can work on that will help us understand viruses and diseases. (Hint, Pardis, hint!)
The primary student collaborators were David and Yakir Reshef. David was a student at MIT when he took my graduate class Algorithms at the End of the Wire, which covers information theory as one of the units. He had already been working with Pardis on data mining problems and ended up working on an early version of MINE as his project for the class. I told him he should continue the project and I'd be happy to help out. It's always nice when class projects turn into papers -- something I try to encourage. This one turned out better than most.
David continued working with his brother Yakir (along with me and Pardis). David and Yakir are both cross-cultural people; Yakir is currently a Fulbright scholar in the Department of Applied Math and Computer Science at Weizmann, after getting his BA in math at Harvard -- but is currently applying to MD/PhD programs. David is getting his MD/PhD here at Harvard-MIT Health Sciences and Technology Program, after having spent the last few years at Oxford on a Marshall doing graduate work in statistics. So between them they definitely provided plenty of glue between me and Pardis. Both of them pushed me to learn a bunch of statistics along the way. I'm not sure I was the best student, but I read a bunch of statistics papers for this work, to know what work was out there on these sorts of problems.
Others also came into the project, the most notable for me being Hilary Finucane -- who I wrote multiple papers with when she was a Harvard undergrad, and who was simultaneously busy obtaining her MSc in theoretical computer science at Weizmann. And who is now engaged to Yakir (they were a couple together back at Harvard) . With two brothers and a fiancee in the mix, the paper was a friendly, family-oriented affair. I also got to meet and work with Eric Lander, who was one of the leaders in sequencing the human genome, and quickly found out how amazing he is.
Like many of my collaborations these days, the work would have been impossible without Skype -- at various points on the project, we had to set up meetings between Boston, Oxford, and Israel, which generally meant at least one group was awake at an unusual hour. But that sort of group commitment helped keep the energy up for the project over the long haul.
The work on MIC and MINE was a multi-year project, and was definitely more effort than most papers I am involved with. On the other hand, because it was a great team to work with, I enjoyed the process. I got to work with a bunch of people with different backgrounds and experiences, all of whom are immensely talented; they pushed me to learn new things so I could keep up. I'm glad the work ended up being published in a prestigious journal -- especially because the students deserve the payoff. But even if it hadn't, it would have been a successful collaboration for me.
Pardis is no stranger to mathematical thinking -- some of her work that she's most well known for is in designing statistical tests to detect mutations at the very short time scale of humans over the last 10,000 years, with the goal being to identify parts of the genome that have undergone natural selection in response to diseases. So while my take was a bit more CS/math focused (what can we prove? how fast/complex is our algorithm?) and hers what a bit more biology/statistics focused (what is this telling us about the data? what data sets can we apply this too?) the lines were pretty blurry. But it did mean I got to pick up a little biology and public health on the way. Who knew that natural selection could be so readily found in humans? Or that the graph of weight vs. income by country has some really unusual characteristics (weight goes up with national income up to some point, but then goes down again; the outliers are the US, and Pacific island nations)? And that you can find genes that are strongly tied to susceptibility to certain viral diseases?
I must admit, it is a bit intimidating when talking to a colleague about your other projects, and I'm explaining cuckoo hashing and Groupon, while she's discussing flying off for the Nth time this year to Africa for her project on how genes are changing in response to Ebola and Lassa viruses. But it's just encouraged me to keep looking for these sorts of broadening opportunities. Maybe someday I'll find a project I too can work on that will help us understand viruses and diseases. (Hint, Pardis, hint!)
The primary student collaborators were David and Yakir Reshef. David was a student at MIT when he took my graduate class Algorithms at the End of the Wire, which covers information theory as one of the units. He had already been working with Pardis on data mining problems and ended up working on an early version of MINE as his project for the class. I told him he should continue the project and I'd be happy to help out. It's always nice when class projects turn into papers -- something I try to encourage. This one turned out better than most.
David continued working with his brother Yakir (along with me and Pardis). David and Yakir are both cross-cultural people; Yakir is currently a Fulbright scholar in the Department of Applied Math and Computer Science at Weizmann, after getting his BA in math at Harvard -- but is currently applying to MD/PhD programs. David is getting his MD/PhD here at Harvard-MIT Health Sciences and Technology Program, after having spent the last few years at Oxford on a Marshall doing graduate work in statistics. So between them they definitely provided plenty of glue between me and Pardis. Both of them pushed me to learn a bunch of statistics along the way. I'm not sure I was the best student, but I read a bunch of statistics papers for this work, to know what work was out there on these sorts of problems.
Others also came into the project, the most notable for me being Hilary Finucane -- who I wrote multiple papers with when she was a Harvard undergrad, and who was simultaneously busy obtaining her MSc in theoretical computer science at Weizmann. And who is now engaged to Yakir (they were a couple together back at Harvard) . With two brothers and a fiancee in the mix, the paper was a friendly, family-oriented affair. I also got to meet and work with Eric Lander, who was one of the leaders in sequencing the human genome, and quickly found out how amazing he is.
Like many of my collaborations these days, the work would have been impossible without Skype -- at various points on the project, we had to set up meetings between Boston, Oxford, and Israel, which generally meant at least one group was awake at an unusual hour. But that sort of group commitment helped keep the energy up for the project over the long haul.
The work on MIC and MINE was a multi-year project, and was definitely more effort than most papers I am involved with. On the other hand, because it was a great team to work with, I enjoyed the process. I got to work with a bunch of people with different backgrounds and experiences, all of whom are immensely talented; they pushed me to learn new things so I could keep up. I'm glad the work ended up being published in a prestigious journal -- especially because the students deserve the payoff. But even if it hadn't, it would have been a successful collaboration for me.
Monday, December 26, 2011
Wasted Hour(s)
Last night I was running some code for a queuing simulation related to some research I'm doing. This is the Nth time I've used this code; I wrote up the basic simulator back in grad school for some of my thesis work (on the power of two choices), and every once in a couple years or so, some project pops up where what I want is some variant of it. So I copy whatever version is lying around, tweak it for the new problem, and off I go.
Today when I was putting together the table the numbers just didn't look right to me. I re-checked the theory and it was clearly telling me that output X should be less than output Y, but that wasn't how the numbers were coming out. Something was wrong somewhere.
After staring at the code a while, and running a few unhelpful tests, I decided to go back to square 1, and just run the code in the "old" configuration, where I knew exactly what I should get. And I didn't get it.
That helped tell me where to look. Sure enough, a couple minutes later, I found the "bad" line of code; last project, I must have wanted to look at queues with constant service times instead of exponential service times, and I had just changed that line; now I needed it changed back. And all is well with the world again.
I'm sure there are some lessons in there somewhere -- about documenting code, about setting things up as parameters instead of hard-wiring things in, all that good stuff one should do but doesn't always. It catches up to you sooner or later. Meanwhile, the code is back to running, and in about 24 hours I'll hopefully have the table I need.
Today when I was putting together the table the numbers just didn't look right to me. I re-checked the theory and it was clearly telling me that output X should be less than output Y, but that wasn't how the numbers were coming out. Something was wrong somewhere.
After staring at the code a while, and running a few unhelpful tests, I decided to go back to square 1, and just run the code in the "old" configuration, where I knew exactly what I should get. And I didn't get it.
That helped tell me where to look. Sure enough, a couple minutes later, I found the "bad" line of code; last project, I must have wanted to look at queues with constant service times instead of exponential service times, and I had just changed that line; now I needed it changed back. And all is well with the world again.
I'm sure there are some lessons in there somewhere -- about documenting code, about setting things up as parameters instead of hard-wiring things in, all that good stuff one should do but doesn't always. It catches up to you sooner or later. Meanwhile, the code is back to running, and in about 24 hours I'll hopefully have the table I need.
Thursday, December 22, 2011
MIC and MINE, a short description
I thought I should give a brief description of MIC and MINE, the topic of our Science paper. Although you're probably better off, if you're interested, looking at our website, http://www.exploredata.net/. Not only does it have a brief description of the algorithm, but now we have a link that gives access to the paper (if you couldn't access it previously) available on this page, thanks to the people at Science.
Our starting point was figuring out what to do with large, multidimensional data sets. If you're given a bunch of data, how do you start to figure out what might be interesting? A natural approach is to calculate some measure on each pair of variables which serves as a proxy for how interesting they are -- where interesting, to us, means that the variables appear dependent in some way. Once you have this, you can pull out the top-scoring pairs and take a closer look.
What properties would we like our measure to have?
First, we would like it to be general, in the sense that it should pick up as diverse a collection of possible associations between variables as possible. The well-known Pearson correlation coefficient, for example, does not have this property -- as you can see from this Wikipedia picture

it's great at picking up linear relationships, but other relationships (periodic sine waves, parabolas, exponential functions, circular associations) it's not so good at.
Second, we would like it to be what we call equitable. By this we mean that scores should degrade with noise at (roughly) the same rate. If you start with a line and start with a sine wave, and add an equivalent amount of noise to both of them in the same way, the resulting scores should be about the same; otherwise the method would give preference to some types of relationships over others.
I should point out that the goal behind these properties is to allow exploration -- the point is you don't know what sort of patterns in the data you should be looking for. If you do know, you're probably better off using a specific tests. If you're looking for linear relationships, Pearson is great -- and there are a large variety of powerful tests that have been developed for specific types of relationships over the years.
Our suggested measure, MIC (maximal information coefficient), is based on mutual information, but is different from it. Our intuition is that if a relationship exists between two variables, then a grid can be drawn on the scatterplot that partitions the data in a way that corresponds to that relationship. Suppose we have a grid, with x rows and y columns; then this grid induces a probability distribution, where the probability associated with a box on the grid is proportional to the number of data points it contains. Let I_G be the mutual information of the grid. We aim to maximize I_G/ log min(x,y) -- this is the MIC score. (We bound x, y values to avoid trivial cases like every point having its own box; see the paper for more details.) MIC values are between 0 and 1, and we can approximately compute MIC values heuristically. Our work shows via a mix of proofs and experiments that MIC appears to have the properties of generality and equitability we desire.
Based on the approach we use to find MIC, we suggest several other possible useful measures, and we refer to the collection as MINE (maximal information-based nonparametric exploration) statistics. For example, MIC - Pearson^2 turns out to be a useful measure for specifically finding nonlinear relationships. When MIC is high (close to 1) and Pearson is low (close to 0), there is a relationship that MIC has found but it is not a linear one; for linear patterns, both MIC and Pearson are high, and so this measure is close to 0. Other measures we have measure things like deviations from monotonicity -- useful for finding periodic relationships.
Should MIC/MINE prove useful, I believe there's lots of theoretical questions left to consider. The approach is currently essentially heuristic, although we do prove a fair number of things about it. Proving more about its properties would be useful, as well as improving the complexity to compute the relevant measures.
Next up: more about the experience of working on this project.
Our starting point was figuring out what to do with large, multidimensional data sets. If you're given a bunch of data, how do you start to figure out what might be interesting? A natural approach is to calculate some measure on each pair of variables which serves as a proxy for how interesting they are -- where interesting, to us, means that the variables appear dependent in some way. Once you have this, you can pull out the top-scoring pairs and take a closer look.
What properties would we like our measure to have?
First, we would like it to be general, in the sense that it should pick up as diverse a collection of possible associations between variables as possible. The well-known Pearson correlation coefficient, for example, does not have this property -- as you can see from this Wikipedia picture
{kind=link}
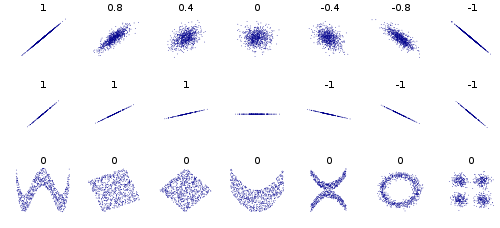
it's great at picking up linear relationships, but other relationships (periodic sine waves, parabolas, exponential functions, circular associations) it's not so good at.
Second, we would like it to be what we call equitable. By this we mean that scores should degrade with noise at (roughly) the same rate. If you start with a line and start with a sine wave, and add an equivalent amount of noise to both of them in the same way, the resulting scores should be about the same; otherwise the method would give preference to some types of relationships over others.
I should point out that the goal behind these properties is to allow exploration -- the point is you don't know what sort of patterns in the data you should be looking for. If you do know, you're probably better off using a specific tests. If you're looking for linear relationships, Pearson is great -- and there are a large variety of powerful tests that have been developed for specific types of relationships over the years.
Our suggested measure, MIC (maximal information coefficient), is based on mutual information, but is different from it. Our intuition is that if a relationship exists between two variables, then a grid can be drawn on the scatterplot that partitions the data in a way that corresponds to that relationship. Suppose we have a grid, with x rows and y columns; then this grid induces a probability distribution, where the probability associated with a box on the grid is proportional to the number of data points it contains. Let I_G be the mutual information of the grid. We aim to maximize I_G/ log min(x,y) -- this is the MIC score. (We bound x, y values to avoid trivial cases like every point having its own box; see the paper for more details.) MIC values are between 0 and 1, and we can approximately compute MIC values heuristically. Our work shows via a mix of proofs and experiments that MIC appears to have the properties of generality and equitability we desire.
Based on the approach we use to find MIC, we suggest several other possible useful measures, and we refer to the collection as MINE (maximal information-based nonparametric exploration) statistics. For example, MIC - Pearson^2 turns out to be a useful measure for specifically finding nonlinear relationships. When MIC is high (close to 1) and Pearson is low (close to 0), there is a relationship that MIC has found but it is not a linear one; for linear patterns, both MIC and Pearson are high, and so this measure is close to 0. Other measures we have measure things like deviations from monotonicity -- useful for finding periodic relationships.
Should MIC/MINE prove useful, I believe there's lots of theoretical questions left to consider. The approach is currently essentially heuristic, although we do prove a fair number of things about it. Proving more about its properties would be useful, as well as improving the complexity to compute the relevant measures.
Next up: more about the experience of working on this project.
Sunday, December 18, 2011
Congratulations to Hanspeter Pfister
Despite our really very good track record for the last decade or so, there are some people out there who remain under the misimpression that it's impossible to get tenure at Harvard.
So I'm very happy to announce that Hanspeter Pfister has achieved the impossible, and is now a tenured Harvard Professor.
Hanspeter works in graphics and visualization, doing the usual sort of things like replacing your face in videos and designing 3-d printers that work like a Star Trek replicator. But he has also developed a large number of collaborations with domain scientists, finding interesting and important visualization problems in things like diagnosing heart disease and mapping the brain.
We're all happy he'll be staying around. Hooray for Hanspeter!
So I'm very happy to announce that Hanspeter Pfister has achieved the impossible, and is now a tenured Harvard Professor.
Hanspeter works in graphics and visualization, doing the usual sort of things like replacing your face in videos and designing 3-d printers that work like a Star Trek replicator. But he has also developed a large number of collaborations with domain scientists, finding interesting and important visualization problems in things like diagnosing heart disease and mapping the brain.
We're all happy he'll be staying around. Hooray for Hanspeter!
Friday, December 16, 2011
This Week, I Am A Scientist
This week, I am a scientist; I know this, because I have an article in Science.
It's nice to have something to point to that my parents can understand. I don't mean they'll understand the paper, but they'll understand that getting a paper in Science is important, more so than my papers that appear other places. And because they're probably reading this, I will also point them to the Globe article appearing today about the work, even though the article rightly focuses on the cool and unusual fact that the lead authors are two brothers, David and Yakir Reshef.
I had been planning to write one or more posts about the paper -- both the technical stuff and the great fun I've been having working with David, Yakir, my long-time colleague Hilary Finucane, the truly amazing systems biology professor Pardis Sabeti, and others on this project. (See Pardis's Wikipedia page or this site to see how Pardis rocks!) But between Science's "news embargo" policies and my own end-of-semester busy-ness, I blew it. I'll try to have them out next week. But for now, for those of you who might be interested, here's the link to the project web page, and here's the abstract:
It's nice to have something to point to that my parents can understand. I don't mean they'll understand the paper, but they'll understand that getting a paper in Science is important, more so than my papers that appear other places. And because they're probably reading this, I will also point them to the Globe article appearing today about the work, even though the article rightly focuses on the cool and unusual fact that the lead authors are two brothers, David and Yakir Reshef.
I had been planning to write one or more posts about the paper -- both the technical stuff and the great fun I've been having working with David, Yakir, my long-time colleague Hilary Finucane, the truly amazing systems biology professor Pardis Sabeti, and others on this project. (See Pardis's Wikipedia page or this site to see how Pardis rocks!) But between Science's "news embargo" policies and my own end-of-semester busy-ness, I blew it. I'll try to have them out next week. But for now, for those of you who might be interested, here's the link to the project web page, and here's the abstract:
Detecting Novel Associations in Large Data Sets
Abstract: Identifying interesting relationships between pairs of variables in large data sets is increasingly important. Here, we present a measure of dependence for two-variable relationships: the maximal information coefficient (MIC). MIC captures a wide range of associations both functional and not, and for functional relationships provides a score that roughly equals the coefficient of determination (R2) of the data relative to the regression function. MIC belongs to a larger class of maximal information-based nonparametric exploration (MINE) statistics for identifying and classifying relationships. We apply MIC and MINE to data sets in global health, gene expression, major-league baseball, and the human gut microbiota and identify known and novel relationships.Thursday, December 15, 2011
Consulting
As I've probably mentioned, I generally enjoy my consulting work. Besides the obvious remunerative aspects, consulting provides challenges, insights, and experiences that are quite different from academic work.
On the other hand, taking red-eyes and having to get up at 4 am for a 6 am flight to a meeting in another city -- both of which I had to do this week -- I could happily do without.
On the other hand, taking red-eyes and having to get up at 4 am for a 6 am flight to a meeting in another city -- both of which I had to do this week -- I could happily do without.
Wednesday, December 14, 2011
Grading
Some folks at the NSDI meeting were nice enough to say that it was nice that I was blogging again. Sadly, I've been under-the-gun busy for the last several weeks, but it was a reminder that I should be getting back to this now and again.
One thing that's taken my time the last week is grading. I was teaching my graduate course this semester, on randomized algorithms and probabilistic analysis, using my book as the base. Unfortunately, I teach this course at most every other year, which means it's hard if not impossible to find a suitable TA. (As for my own students, Zhenming is on an internship this semester; Justin's on fellowship and essentially required not to TA. Also, both have been extremely busy this semester doing really great work, so why would I want them to TA instead of doing their research now anyway?) So this year I didn't have one. Which means I graded things myself.
It's been a while since I've graded a whole course. I do grade exams (with the TAs) and one full assignment (myself) every year in my undergraduate class. But grading every week is really at least as bad as having to do homework every week. I'd say worse; very little interesting thinking involved, just a lot of reading, checking, and moving papers or files around in a time-consuming fashion. Somehow, though, I don't think the students sympathize.
I think I remember one graduate class in Berkeley where a student (or maybe a group of students) were required to take on the grading every assignment. I like that plan. In fact, right now I like any plan that doesn't involve me grading the next time I teach this class. One plan is of course no/minimal homework, or homework without grades. However, I do believe students learn by doing homework, and I've found that in most circumstances a grade is the motivator that makes them get the homework done, so I'll have to find a plan that involves grading somehow.
One thing that's taken my time the last week is grading. I was teaching my graduate course this semester, on randomized algorithms and probabilistic analysis, using my book as the base. Unfortunately, I teach this course at most every other year, which means it's hard if not impossible to find a suitable TA. (As for my own students, Zhenming is on an internship this semester; Justin's on fellowship and essentially required not to TA. Also, both have been extremely busy this semester doing really great work, so why would I want them to TA instead of doing their research now anyway?) So this year I didn't have one. Which means I graded things myself.
It's been a while since I've graded a whole course. I do grade exams (with the TAs) and one full assignment (myself) every year in my undergraduate class. But grading every week is really at least as bad as having to do homework every week. I'd say worse; very little interesting thinking involved, just a lot of reading, checking, and moving papers or files around in a time-consuming fashion. Somehow, though, I don't think the students sympathize.
I think I remember one graduate class in Berkeley where a student (or maybe a group of students) were required to take on the grading every assignment. I like that plan. In fact, right now I like any plan that doesn't involve me grading the next time I teach this class. One plan is of course no/minimal homework, or homework without grades. However, I do believe students learn by doing homework, and I've found that in most circumstances a grade is the motivator that makes them get the homework done, so I'll have to find a plan that involves grading somehow.
Tuesday, December 06, 2011
Plane Work
I dislike flying, but I have a few flights coming up.
I find that engaging in "real thinking" about problems while on a plane is generally beyond me. (I'm jealous of all of you that somehow manage this.) Similarly (or Even) writing code takes more focus than I can manage on a plane. But I do try to make my plane time useful.
Luckily, it's the end of the semester, so I think I'll be bringing the last homeworks and final exams to grade on board this time around.
Reviewing (conference) papers is something I manage on plane flights. I'm sure that says something about the level of my reviews. On the plane my goal isn't to read the paper in same depth that I'd read a paper I'm trying to understand for my research; it's to assign a score (sort) and write down useful comments. (Which, I guess, is my goal for conference reviews off the plane as well. And why I wouldn't do journal reviews on planes.) If you get a review you don't like, I suppose now you can always assume you can assign the blame to the fact that I was on a long plane flight. But I don't think I'll have any reviews this month.
Reviewing proposals is even better than reviewing conference papers on a plane. I often get foreign governments sending me proposals to review for them, and they often pay some nominal amount. If I know I have a flight coming up, I sometimes say yes. It makes me feel like I'm doing something useful on the flight, and even getting paid for it.
When all that fails, I try to read a mindless book. (It's always good to have one on hand for those interminable periods where your electronic devices must be turned off.) I slipped up and started reading V is for Vengeance at home. (I think I've read all the Kinsey Millhone books from A, but I started at around H, and can't recall if I found all the earlier ones. I wonder what she'll do after Z?) I've been saving Mockingjay
at home. (I think I've read all the Kinsey Millhone books from A, but I started at around H, and can't recall if I found all the earlier ones. I wonder what she'll do after Z?) I've been saving Mockingjay  for a plane flight though. (I try to read what my kids read. So I'm also quite familiar with Percy Jackson.) I've read most of Robert Parker's books
for a plane flight though. (I try to read what my kids read. So I'm also quite familiar with Percy Jackson.) I've read most of Robert Parker's books in the air.
in the air.
Finally, sometimes, I fall asleep. I've gotten reasonably good at sleeping on flights. Then I don't get the work I thought I'd get done on the plane done. But it definitely feels like a good use for the time.
I find that engaging in "real thinking" about problems while on a plane is generally beyond me. (I'm jealous of all of you that somehow manage this.) Similarly (or Even) writing code takes more focus than I can manage on a plane. But I do try to make my plane time useful.
Luckily, it's the end of the semester, so I think I'll be bringing the last homeworks and final exams to grade on board this time around.
Reviewing (conference) papers is something I manage on plane flights. I'm sure that says something about the level of my reviews. On the plane my goal isn't to read the paper in same depth that I'd read a paper I'm trying to understand for my research; it's to assign a score (sort) and write down useful comments. (Which, I guess, is my goal for conference reviews off the plane as well. And why I wouldn't do journal reviews on planes.) If you get a review you don't like, I suppose now you can always assume you can assign the blame to the fact that I was on a long plane flight. But I don't think I'll have any reviews this month.
Reviewing proposals is even better than reviewing conference papers on a plane. I often get foreign governments sending me proposals to review for them, and they often pay some nominal amount. If I know I have a flight coming up, I sometimes say yes. It makes me feel like I'm doing something useful on the flight, and even getting paid for it.
When all that fails, I try to read a mindless book. (It's always good to have one on hand for those interminable periods where your electronic devices must be turned off.) I slipped up and started reading V is for Vengeance
Finally, sometimes, I fall asleep. I've gotten reasonably good at sleeping on flights. Then I don't get the work I thought I'd get done on the plane done. But it definitely feels like a good use for the time.
Saturday, December 03, 2011
The End (of the Semester) is Nigh
If you've missed it (which probably means you're not a theorist and/or a blog-reader), you should check out the (entertaining) controversies of the last week or two, starting with Oded's guest post on the decline of intellectual values in Theoretical Computer Science, and then whether a lowering of the matrix multiplication exponent counts as a "breakthrough" (see follow-up blog posts here, here, and here).
I've enjoyed watching them develop, but have been happy to let them go on without putting a big target on my back. I've also been too busy getting through my last lectures, making up a final exam, trying to get some grant proposals ready on ridiculous deadlines, and dealing with administrative issues like prepping slides for an end-of-semester faculty retreat. Occasionally I try to fit in meeting with students and (last of all) working on research. I know the end of the semester is a mad rush for students, finishing projects and papers and getting ready for exams. Sadly, I feel the same way this year. Another week or two and it will be all over, and like the students I think I'm ready to let things go for a couple of weeks of holiday time.
But probably I'll stay up late after the kids are in bed and try to do some of that research stuff. There are some fun problems that have been waiting for attention most of the semester, and I'd like to see what happens if I'm finally able to give them some.
I've enjoyed watching them develop, but have been happy to let them go on without putting a big target on my back. I've also been too busy getting through my last lectures, making up a final exam, trying to get some grant proposals ready on ridiculous deadlines, and dealing with administrative issues like prepping slides for an end-of-semester faculty retreat. Occasionally I try to fit in meeting with students and (last of all) working on research. I know the end of the semester is a mad rush for students, finishing projects and papers and getting ready for exams. Sadly, I feel the same way this year. Another week or two and it will be all over, and like the students I think I'm ready to let things go for a couple of weeks of holiday time.
But probably I'll stay up late after the kids are in bed and try to do some of that research stuff. There are some fun problems that have been waiting for attention most of the semester, and I'd like to see what happens if I'm finally able to give them some.
Thursday, December 01, 2011
Letters of Recommendation Time. Ugh.
I don't mind writing letters of recommendation for students. It's part of the job. It's a good thing to do.
I just mind dealing with the new e-application sites. I'd rather hand my letter off to an admin and have them send it. The good old days...
To see what I'm talking about, I'm now a huge non-fan of Embark -- here's their "help page", which explains that I may have to wait 5+ minutes for my pdf to upload, without really explaining why
I just mind dealing with the new e-application sites. I'd rather hand my letter off to an admin and have them send it. The good old days...
To see what I'm talking about, I'm now a huge non-fan of Embark -- here's their "help page", which explains that I may have to wait 5+ minutes for my pdf to upload, without really explaining why
Monday, November 21, 2011
Round Two Reviewing : An Exercise in Conditional Probabilities
We're in "round 2" of reviews for NSDI, and it's brought up a problem for me I've noticed before. I worry that, subconsciously, I'm inclined to give papers I read on the second round a higher score, since I'm swayed by the fact that they've in fact made it to the second round.
I wonder if anyone in the PC world has done any testing of this to see if it's a real phenomenon. Are second round reviews on a set of papers statistically different from the first round of reviews? I would bet yes, even controlling for the fact that the papers made it to the second round. In particular, I'd suspect it's much harder for people to give a score of 1 (=reject) to a second round paper.
One could imagine attempting to test for this by sticking a few obvious rejects from the first round into the second round reviews. Indeed, perhaps one should make this part of the process: randomly select a few clear rejects to go into round two, and announce that you're doing this to the PC. Then they might not feel so averse to assigning a score of 1 in the second round.
One joy in the second round reviews is once you submit a review you get to see the first round reviews. So far, I feel I've been calling them fairly; when I haven't liked a second round paper, the first round reviews seem to confirm my opinion. So perhaps (with some effort) I'm keeping my subconscious at bay successfully, and not conditioning on the fact that it's a round 2 review.
I wonder if anyone in the PC world has done any testing of this to see if it's a real phenomenon. Are second round reviews on a set of papers statistically different from the first round of reviews? I would bet yes, even controlling for the fact that the papers made it to the second round. In particular, I'd suspect it's much harder for people to give a score of 1 (=reject) to a second round paper.
One could imagine attempting to test for this by sticking a few obvious rejects from the first round into the second round reviews. Indeed, perhaps one should make this part of the process: randomly select a few clear rejects to go into round two, and announce that you're doing this to the PC. Then they might not feel so averse to assigning a score of 1 in the second round.
One joy in the second round reviews is once you submit a review you get to see the first round reviews. So far, I feel I've been calling them fairly; when I haven't liked a second round paper, the first round reviews seem to confirm my opinion. So perhaps (with some effort) I'm keeping my subconscious at bay successfully, and not conditioning on the fact that it's a round 2 review.
Wednesday, November 16, 2011
Public University Budgets
Another topic that arose in conversations during my visit to Wisconsin was the issue of budgets, and in particular the large-scale cuts that many of the best US public school are having to deal with. It's not hard to find information on this. My first search on Google yielded this article about what's going on in Wisconsin (taking choice quotes, not the full article; it's from June).
Public universities generally have been faring quite badly in the current financial crisis. I have a deep pro-education bias, unsurprisingly, so I find this depressing. But also, in my mind, it's just not sound financial sense. I believe these cuts today will yield a corresponding decline in Wisconsin's economy tomorrow, for some appropriate notion of tomorrow. A dollar spent on education should be worth... well, I don't know how much it should be worth, but my guess is the multiplier on the dollar is pretty high. I'd like more information to back that up. If you know of any studies that demonstrate the payoff for education -- the sort of thing all of us in the education field should have on hand when discussions like this come up -- please leave them in the comments. It would be nice to have a collection handy.
Wis. Gov. signs budget cutting education $1.85BI'm sure the children and grandchildren he talks about, who will have to face the new challenge of increased global competition with an increasingly better educated non-Wisconsin population instead of the challenges being faced today, will be very appreciative.
Democrats assailed the budget as an attack on middle class values since it cuts funding for public schools by $800 million, reduces funding to the UW system by $250 million and cuts tax credits for poor people.
It also reduces the amount schools can collect from property taxes and other revenue combined, which translates into another education cut of about $800 million. While schools are seeing deep cuts, Walker's budget extends tax breaks to manufacturers, multistate corporations and investors.
"As a state, we can choose to take the easy road and push off the tough decisions and pass the buck to future generations, or we can step up to the plate and make the tough decisions today," Walker said in prepared remarks. "Our budget chooses to fix our problems now, so that our children and our grandchildren don't face the same challenges we face today."
Public universities generally have been faring quite badly in the current financial crisis. I have a deep pro-education bias, unsurprisingly, so I find this depressing. But also, in my mind, it's just not sound financial sense. I believe these cuts today will yield a corresponding decline in Wisconsin's economy tomorrow, for some appropriate notion of tomorrow. A dollar spent on education should be worth... well, I don't know how much it should be worth, but my guess is the multiplier on the dollar is pretty high. I'd like more information to back that up. If you know of any studies that demonstrate the payoff for education -- the sort of thing all of us in the education field should have on hand when discussions like this come up -- please leave them in the comments. It would be nice to have a collection handy.
Tuesday, November 15, 2011
Yes, We Are Hiring (2012)
Harvard CS will be hiring this year.
One tenure-track position is geared toward systems, very broadly defined.
A second tenure-track position is in Applied Math, where we're aiming for a "discrete applied math" person. The right CS theory person could fit just fine. And if we see great CS theory people who really want to be in CS rather than AM, we should be able to find a way to make that work.
Here's the link to the ad for both. Here's the URL: https://www.seas.harvard.edu/csjobs. And the ad text follows. Spread the word!
Candidates are required to have a PhD or an equivalent terminal degree, or to be able to certify that they will receive the degree within one year of the expected start date. In addition, we seek candidates who have an outstanding research record and a strong commitment to undergraduate teaching and graduate training.
Position 1: Computer Science. We welcome outstanding applicants in all areas of computer science. We are particularly interested in systems, broadly defined, including compilers, programming languages, distributed systems, databases, networking, and operating systems. Applicants will apply online at http://academicpositions.harvard.edu/postings/3825.
Position 2: Applied Math/Computer Science. We welcome outstanding applicants in all areas of applied mathematics or theoretical computer science. We are particularly interested in topics at the boundary or intersection of these fields, including optimization, applied probability, scientific computing, combinatorics and graph theory, approximation algorithms, and numerical analysis. Applicants will apply on-line at http://academicpositions.harvard.edu/postings/3824.
In terms of applications, areas of interest include computational science, engineering, or the social sciences. We encourage applications from candidates whose research examines computational issues raised by very large data sets or massively parallel processing.
The Computer Science and Applied Mathematics programs at Harvard University benefit from outstanding undergraduate and graduate students, an excellent location, significant industrial collaboration, and substantial support from the Harvard School of Engineering and Applied Sciences. Information about Harvard's current faculty, research, and educational programs is available at http://www.seas.harvard.edu.
Required documents include a CV, a statement of research and teaching interests, up to three representative papers, and names and contact information for at least three references.
Applications will be reviewed as they are received. The review of applications will begin on December 15, 2011, and applicants are strongly encouraged to submit applications by that date; however, applications will continue to be accepted at least until January 15, 2012.
Harvard is an Equal Opportunity/ Affirmative Action Employer. Applications from women and minority candidates are strongly encouraged.
One tenure-track position is geared toward systems, very broadly defined.
A second tenure-track position is in Applied Math, where we're aiming for a "discrete applied math" person. The right CS theory person could fit just fine. And if we see great CS theory people who really want to be in CS rather than AM, we should be able to find a way to make that work.
Here's the link to the ad for both. Here's the URL: https://www.seas.harvard.edu/csjobs. And the ad text follows. Spread the word!
Tenure-Track Positions in Computer Science and Applied Mathematics
The Harvard School of Engineering and Applied Sciences (SEAS) seeks applicants for positions at the level of tenure-track assistant professor in the fields of Computer Science and Applied Math/Computer Science, with an expected start date of July 1, 2012.Candidates are required to have a PhD or an equivalent terminal degree, or to be able to certify that they will receive the degree within one year of the expected start date. In addition, we seek candidates who have an outstanding research record and a strong commitment to undergraduate teaching and graduate training.
Position 1: Computer Science. We welcome outstanding applicants in all areas of computer science. We are particularly interested in systems, broadly defined, including compilers, programming languages, distributed systems, databases, networking, and operating systems. Applicants will apply online at http://academicpositions.harvard.edu/postings/3825.
Position 2: Applied Math/Computer Science. We welcome outstanding applicants in all areas of applied mathematics or theoretical computer science. We are particularly interested in topics at the boundary or intersection of these fields, including optimization, applied probability, scientific computing, combinatorics and graph theory, approximation algorithms, and numerical analysis. Applicants will apply on-line at http://academicpositions.harvard.edu/postings/3824.
In terms of applications, areas of interest include computational science, engineering, or the social sciences. We encourage applications from candidates whose research examines computational issues raised by very large data sets or massively parallel processing.
The Computer Science and Applied Mathematics programs at Harvard University benefit from outstanding undergraduate and graduate students, an excellent location, significant industrial collaboration, and substantial support from the Harvard School of Engineering and Applied Sciences. Information about Harvard's current faculty, research, and educational programs is available at http://www.seas.harvard.edu.
Required documents include a CV, a statement of research and teaching interests, up to three representative papers, and names and contact information for at least three references.
Applications will be reviewed as they are received. The review of applications will begin on December 15, 2011, and applicants are strongly encouraged to submit applications by that date; however, applications will continue to be accepted at least until January 15, 2012.
Harvard is an Equal Opportunity/ Affirmative Action Employer. Applications from women and minority candidates are strongly encouraged.
Monday, November 14, 2011
Public Salary Information
While visiting Wisconsin last week (enjoying very pleasant company and conversation), various issues came up.
For one, I was reminded (or recalled) that as a public university, University of Wisconsin-Madison salaries are available online. I can understand why salaries of elected public officials, and the people they hire, should be public information. Transparency in politics is a valuable thing.
But I don't see that professor's salaries should be public. Perhaps this is merely a personal bias; I wouldn't want MY salary to be public information.** I also don't use Facebook, so perhaps I'm just a 20th century privacy-desiring relic. Perhaps more reasonably, I don't see university faculty as political employees, and therefore think they -- as well as the university -- should enjoy the same privacy for salary information that other employers and employees enjoy.
Perhaps, however, I'm just wrong, and transparency of salary information is good for all. I'm willing to entertain that thought. Certainly I think the Taulbee survey that aggregates salary information is useful and good information, for both universities and faculty, as I think there's a shortage of accurate comparative salary information for faculty positions (as compared to other jobs), and the Taulbee survey provides an important information baseline. Is it so far to go from there to individual's salaries?
How do those of you at schools where your salary information is public information feel about this? And the rest of you?
** Although perhaps in some sense it is. I don't believe my NSF grant budgets are publicly accessible information, but at some point, I was informed by my university that a Freedom of Information Act request had been made for one of my funded proposals. (I don't know why, though I have some suppositions.) The university filed paperwork to hopefully make sure that personal information, including my salary, would be redacted.
For one, I was reminded (or recalled) that as a public university, University of Wisconsin-Madison salaries are available online. I can understand why salaries of elected public officials, and the people they hire, should be public information. Transparency in politics is a valuable thing.
But I don't see that professor's salaries should be public. Perhaps this is merely a personal bias; I wouldn't want MY salary to be public information.** I also don't use Facebook, so perhaps I'm just a 20th century privacy-desiring relic. Perhaps more reasonably, I don't see university faculty as political employees, and therefore think they -- as well as the university -- should enjoy the same privacy for salary information that other employers and employees enjoy.
Perhaps, however, I'm just wrong, and transparency of salary information is good for all. I'm willing to entertain that thought. Certainly I think the Taulbee survey that aggregates salary information is useful and good information, for both universities and faculty, as I think there's a shortage of accurate comparative salary information for faculty positions (as compared to other jobs), and the Taulbee survey provides an important information baseline. Is it so far to go from there to individual's salaries?
How do those of you at schools where your salary information is public information feel about this? And the rest of you?
** Although perhaps in some sense it is. I don't believe my NSF grant budgets are publicly accessible information, but at some point, I was informed by my university that a Freedom of Information Act request had been made for one of my funded proposals. (I don't know why, though I have some suppositions.) The university filed paperwork to hopefully make sure that personal information, including my salary, would be redacted.
Thursday, November 10, 2011
CAEC: First Cambridge Area Economics and Computation Day
Wednesday, November 09, 2011
Programming for Non-Programming Exercises
One of the exercises I assigned last week proved interesting:
Consider n points on a circle, labeled clockwise from 0 to n-1. Initially a wolf begins at 0 and there is a sheep at each of the remaining n-1 points. The wolf takes a random walk on the circle; at each step, it moves with probability 1/2 to one neighbor and with probability 1/2 to the other neighbor. (0 and n-1 are neighbors.) The first time the wolf visits any point it eats the sheep that is there. (The wolf can return to points with no sheep.) Which sheep is most likely to be the last eaten?
If you haven't seen it before, you might try it; don't put the answer in the comments, though, since I'll use the problem again.
While grading the assignment, I found a number of students had simulated the process, figured out the answer from the simulations, and then used that knowledge to prove the desired result. The problem didn't ask for them to do it, but they did it themselves.
That was great (and I told them so). That's how solving research problems often works for me. I have to understand what's going on, and in many cases, that understanding comes about by simulating a process to figure out how things behave. Then I go back and try to prove what I think I'm seeing in the simulations.
My worry, though, is that the students that did it this way were primarily the "non-theorists" in the class, who did it because they knew they didn't know the answer, and thought it was easier to code to figure it out. And that the "theorists" in the class correspondingly thought they knew the answer (rightly or wrongly) and went ahead with the calculations without doing a simulation. That's not necessarily a bad thing, certainly not for this problem (which is easy enough), but I'd also like for the theorists to also get into a mindset of doing simulations in this sort of setting, both as a tool to gain insight before trying to prove things and as a check on their proofs.
I think they're probably getting the lesson from other, harder exercises I give. Still, it was nice that a number of people in the class went that direction (and thought to write it down in their assignment).
Consider n points on a circle, labeled clockwise from 0 to n-1. Initially a wolf begins at 0 and there is a sheep at each of the remaining n-1 points. The wolf takes a random walk on the circle; at each step, it moves with probability 1/2 to one neighbor and with probability 1/2 to the other neighbor. (0 and n-1 are neighbors.) The first time the wolf visits any point it eats the sheep that is there. (The wolf can return to points with no sheep.) Which sheep is most likely to be the last eaten?
If you haven't seen it before, you might try it; don't put the answer in the comments, though, since I'll use the problem again.
While grading the assignment, I found a number of students had simulated the process, figured out the answer from the simulations, and then used that knowledge to prove the desired result. The problem didn't ask for them to do it, but they did it themselves.
That was great (and I told them so). That's how solving research problems often works for me. I have to understand what's going on, and in many cases, that understanding comes about by simulating a process to figure out how things behave. Then I go back and try to prove what I think I'm seeing in the simulations.
My worry, though, is that the students that did it this way were primarily the "non-theorists" in the class, who did it because they knew they didn't know the answer, and thought it was easier to code to figure it out. And that the "theorists" in the class correspondingly thought they knew the answer (rightly or wrongly) and went ahead with the calculations without doing a simulation. That's not necessarily a bad thing, certainly not for this problem (which is easy enough), but I'd also like for the theorists to also get into a mindset of doing simulations in this sort of setting, both as a tool to gain insight before trying to prove things and as a check on their proofs.
I think they're probably getting the lesson from other, harder exercises I give. Still, it was nice that a number of people in the class went that direction (and thought to write it down in their assignment).
Monday, November 07, 2011
A Tale of Talks
A bunch of talks today.
Carla Gomes gave a talk at CRCS (Harvard's Center for Research on Computation and Society) to talk about her work on computational sustainability -- interdisciplinary research with "the overall goal of developing computational models, methods, and tools to help manage the balance between environmental, economic, and societal needs for sustainable development." How to use optimization, machine learning, and math and computation more generally to help with problems in "the real world", like designing paths for animal migration or designing control systems for energy-efficient buildings. Fun stuff.
Then I had to take Harvard's M2 shuttle over to the Medical School Area for the Broad Institute's annual retreat. Some students who I have been working with on a project spanning systems biology, computer science, and statistics were giving a 15-minute presentation of their results. (More on the work at some later date.) The scale there is a bit larger than I'm used to; I think over 1000 people were listening to the talk, which might well make it the most seen presentation of my work (even if we sum over multiple presentations of the same talk). Happily, the students really nailed it, both in the presentations and the follow-up Q and A.
Then the shuttle back for Mark Zuckerberg's Q and A session at Harvard. I don't think I've seen him speak before, and he's actually much more well spoken than one might expect if you saw The Social Network. He was entertaining and captivating, and I'm sure inspired many of our students. It was a full room -- you needed to get a ticket to get in. I understand recruiting sessions with students are taking place sometime after. If there are good writeups I'll link to one here later.
I also have my own talks to work on. I'll be giving two talks at U. of Wisconsin this week. One "old" talk on cuckoo hashing, and one "new" talk on verification using streaming interactive proofs. Come on by if you're in the area. (Of course, I suspect if you're in the area, you're probably a student or faculty member of U. of Wisconsin.)
Carla Gomes gave a talk at CRCS (Harvard's Center for Research on Computation and Society) to talk about her work on computational sustainability -- interdisciplinary research with "the overall goal of developing computational models, methods, and tools to help manage the balance between environmental, economic, and societal needs for sustainable development." How to use optimization, machine learning, and math and computation more generally to help with problems in "the real world", like designing paths for animal migration or designing control systems for energy-efficient buildings. Fun stuff.
Then I had to take Harvard's M2 shuttle over to the Medical School Area for the Broad Institute's annual retreat. Some students who I have been working with on a project spanning systems biology, computer science, and statistics were giving a 15-minute presentation of their results. (More on the work at some later date.) The scale there is a bit larger than I'm used to; I think over 1000 people were listening to the talk, which might well make it the most seen presentation of my work (even if we sum over multiple presentations of the same talk). Happily, the students really nailed it, both in the presentations and the follow-up Q and A.
Then the shuttle back for Mark Zuckerberg's Q and A session at Harvard. I don't think I've seen him speak before, and he's actually much more well spoken than one might expect if you saw The Social Network. He was entertaining and captivating, and I'm sure inspired many of our students. It was a full room -- you needed to get a ticket to get in. I understand recruiting sessions with students are taking place sometime after. If there are good writeups I'll link to one here later.
I also have my own talks to work on. I'll be giving two talks at U. of Wisconsin this week. One "old" talk on cuckoo hashing, and one "new" talk on verification using streaming interactive proofs. Come on by if you're in the area. (Of course, I suspect if you're in the area, you're probably a student or faculty member of U. of Wisconsin.)
Friday, November 04, 2011
Funny E-mail of the Day
I've having some issues getting straight answers over e-mail from an administrator in some Harvard office I'm dealing with. This morning, I found the following e-mail in my inbox:
Well, now, this is entirely the problem, isn't it?
Dear Mmichael,
To be clear,
Sent from my iPad
Well, now, this is entirely the problem, isn't it?
Wednesday, November 02, 2011
This Week, We Were Doing Security
If you look on Yelp's engineering blog (http://engineeringblog.yelp.
Before beginning, though, we should say that Yelp's team responded in what seems to us to be an exemplary fashion. After we contacted them, Michael Stoppelman and members of the engineering staff listened to our presentation and description of the vulnerability seriously, and, as they describe in their blog post, took immediate action to correct the problem. While it would be fun to have a security horror story to tell (right around Halloween) of a big company not taking the leakage of user information, or us as researchers, seriously, that absolutely was not the case here. Indeed, when we expressed that we should make the issue public after the problem was fixed, both to transparently inform their users and to possibly help prevent a similar problem on other web sites, they agreed to write a blog post about it, and let us read the copy in advance to make changes or offer suggestions -- and except for making sure Harvard, Yale, and Boston University were all credited, we didn't have any to add.
As people may know from our previous work, we have been studying sites such as Yelp, as they provide an interesting case study as a social network that provides economic information in the form of reviews. As part of our research and data collection, Giorgos was looking at their various interfaces, including the Yelp mobile web site. To be clear, he was not ``hacking'' the site in any way, just interacting with it via a standard browser and normal HTTP requests. He found that when he checked a restaurant for reviews, and subsequently clicked on the button asking for more reviews, entire reviewer records were leaked in JSON format, in the manner described in Yelp's blog post. While this data was present in HTTP replies, and was visible to an HTTP logger such as Firebug for Firefox, or via the built-in logger for Chrome, ordinary users accessing the site from a device such as an iPhone would not observe sensitive information, as client-side Javascript displayed only the non-sensitive information (such as the review text, date, and the user's handle). This example shows the importance of having multiple redundant layers of security when handling personally identifiable information; in the Yelp post, they describe the redundancies they have added to prevent such leakage in the future.
While there was no financial information involved, it seemed to us to be a severe hole, in that personally identifiable information was being sent in the clear in response to a normal and seemingly not infrequent user request. We spent some time verifying what we saw, checking that we were not mistaken and that the vulnerability could potentially leak information at scale. When we were fully convinced the problem was both real and significant, we contacted Yelp.
We did have concerns as we went; we have heard stories of some businesses blaming the messenger when approached with significant security issues. We were pleased that Yelp responded by thanking us rather than blaming us. In our minds, this was a very positive interaction between university researchers and an Internet business.
Giving credit where credit is due, Giorgos deserves the lauds for finding the problem and thereby protecting a lot of user data.
Before beginning, though, we should say that Yelp's team responded in what seems to us to be an exemplary fashion. After we contacted them, Michael Stoppelman and members of the engineering staff listened to our presentation and description of the vulnerability seriously, and, as they describe in their blog post, took immediate action to correct the problem. While it would be fun to have a security horror story to tell (right around Halloween) of a big company not taking the leakage of user information, or us as researchers, seriously, that absolutely was not the case here. Indeed, when we expressed that we should make the issue public after the problem was fixed, both to transparently inform their users and to possibly help prevent a similar problem on other web sites, they agreed to write a blog post about it, and let us read the copy in advance to make changes or offer suggestions -- and except for making sure Harvard, Yale, and Boston University were all credited, we didn't have any to add.
As people may know from our previous work, we have been studying sites such as Yelp, as they provide an interesting case study as a social network that provides economic information in the form of reviews. As part of our research and data collection, Giorgos was looking at their various interfaces, including the Yelp mobile web site. To be clear, he was not ``hacking'' the site in any way, just interacting with it via a standard browser and normal HTTP requests. He found that when he checked a restaurant for reviews, and subsequently clicked on the button asking for more reviews, entire reviewer records were leaked in JSON format, in the manner described in Yelp's blog post. While this data was present in HTTP replies, and was visible to an HTTP logger such as Firebug for Firefox, or via the built-in logger for Chrome, ordinary users accessing the site from a device such as an iPhone would not observe sensitive information, as client-side Javascript displayed only the non-sensitive information (such as the review text, date, and the user's handle). This example shows the importance of having multiple redundant layers of security when handling personally identifiable information; in the Yelp post, they describe the redundancies they have added to prevent such leakage in the future.
While there was no financial information involved, it seemed to us to be a severe hole, in that personally identifiable information was being sent in the clear in response to a normal and seemingly not infrequent user request. We spent some time verifying what we saw, checking that we were not mistaken and that the vulnerability could potentially leak information at scale. When we were fully convinced the problem was both real and significant, we contacted Yelp.
We did have concerns as we went; we have heard stories of some businesses blaming the messenger when approached with significant security issues. We were pleased that Yelp responded by thanking us rather than blaming us. In our minds, this was a very positive interaction between university researchers and an Internet business.
Giving credit where credit is due, Giorgos deserves the lauds for finding the problem and thereby protecting a lot of user data.
Thursday, October 27, 2011
Lisa Randall on the Daily Show
Last night's Daily Show (link to full episode) was on fire.
The first segment was focused on SCIENCE! The part with Aasaf Mandvi was simultaneously hysterical and very, very, very sad.
The last segment had guest Lisa Randall -- Harvard physicist and author of the new book Knocking on Heaven's Door: How Physics and Scientific Thinking Illuminate the Universe and the Modern World as well as the old book Warped Passages: Unraveling the Mysteries of the Universe's Hidden Dimensions -- talking about science also. While I understand Lisa has many tremendous accomplishments, appearing on the Daily Show is the one I am jealous of.
as well as the old book Warped Passages: Unraveling the Mysteries of the Universe's Hidden Dimensions -- talking about science also. While I understand Lisa has many tremendous accomplishments, appearing on the Daily Show is the one I am jealous of.
The first segment was focused on SCIENCE! The part with Aasaf Mandvi was simultaneously hysterical and very, very, very sad.
The last segment had guest Lisa Randall -- Harvard physicist and author of the new book Knocking on Heaven's Door: How Physics and Scientific Thinking Illuminate the Universe and the Modern World
Wednesday, October 26, 2011
Students are Awesome(ly Productive Right Now)
What's the use of a blog if you can't brag about your students? And my students have all been doing great stuff, so I'm excited to let others know about their work. In random order...
Zhenming Liu's paper Information Dissemination via Random Walks in d-Dimensional Space will be appearing in SODA 2012. It looks at a very natural random walk diffusion question that hadn't been solved. Here's the arxiv version, and a slightly edited down abstract:
Zhenming Liu's paper Information Dissemination via Random Walks in d-Dimensional Space will be appearing in SODA 2012. It looks at a very natural random walk diffusion question that hadn't been solved. Here's the arxiv version, and a slightly edited down abstract:
We study a natural information dissemination problem for multiple mobile agents in a bounded Euclidean space. Agents are placed uniformly at random in the $d$-dimensional space $\{-n, ..., n\}^d$ at time zero, and one of the agents holds a piece of information to be disseminated. All the agents then perform independent random walks over the space, and the information is transmitted from one agent to another if the two agents are sufficiently close. We wish to bound the total time before all agents receive the information (with high probability). Our work extends Pettarin et al.'s work, which solved the problem for $d \leq 2$. We present tight bounds up to polylogarithmic factors for the case $d \geq 3$.Justin Thaler's paper on Practical Verified Computation with Streaming Interactive Proof was accepted to ITCS 2012. I think part of its "innovation" is how well Justin puts together the theory with the implementation, showing how practical this line of work could be. Here's the arxiv version, and again a slightly edited down abstract:
When delegating computation to a service provider, as in cloud computing, we seek some reassurance that the output is correct and complete. Yet recomputing the output as a check is inefficient and expensive, and it may not even be feasible to store all the data locally. We are therefore interested in proof systems which allow a service provider to prove the correctness of its output to a streaming (sublinear space) user, who cannot store the full input or perform the full computation herself. Our approach is two-fold. First, we describe a carefully chosen instantiation of one of the most efficient general-purpose constructions for arbitrary computations (streaming or otherwise), due to Goldwasser, Kalai, and Rothblum. This requires several new insights to make the methodology more practical. Our experimental results demonstrate that a practical general-purpose protocol for verifiable computation may be significantly closer to reality than previously realized. Second, we describe techniques that achieve genuine scalability for protocols fine-tuned for specific important problems in streaming and database processing.Finally, Giorgos Zervas's work on Daily Deals: Prediction, Social Diffusion, and Reputational Ramifications, which I've already discussed on the blog since it got so much press play, was also just accepted to WSDM. Giorgos is no longer my student, but working with me and Joan Feigenbaum as a postdoc, so I'll count him in the mix.
Tuesday, October 25, 2011
An Exceptional Exponential Embedding
This week in class I get to teach one of my favorite probability arguments, which makes use of a very unusual embedding. Here's a short description (for the longer description, see the book or the original paper, where the idea is ascribed to Rubin).
or the original paper, where the idea is ascribed to Rubin).
The setting is balls and bins with feedback: I have two bins, and I'm repeatedly randomly throwing balls into the bins one at at time. When there are x balls in bin 1 and y balls in bin 2, the probability the ball I throw lands in bin 1 is x^p/(x^p+y^p), and the probability it lands in bin 2 is y^p/(x^p + y^p). Initially both bins start with one ball. The goal is to show that when p is greater than 1, at some point, one bin gets all the remaining balls thrown. That is, when there's positive feedback, so the more balls you have the more likely it is that you'll get the next one in a super-linear fashion, eventually the system becomes winner-take-all.
We use the following "exponential embedding". Consider the following process for bin 1. At time 0, we associated an an exponentially distributed random variable X_1 with mean 1 = 1/1^p with the bin. The "time" that bin 1 receives its next ball is X_1. Now it has two balls. We then associate an exponentially distributed random variable X_2 with mean 1/2^p with the bin. And so on.
Do the same thing with bin 2, using random variables Y_1, Y_2, ...
Now, at any point in time, due to the properties of the exponential distribution -- namely, it's memoryless, and the minimum of two exponentials with mean a_1 and a_2 will be the first with probability proportional to 1/a_1 and the second with probability 1/a_2 -- if the loads in the bins are x for bin 1 and y for bin 2, then the next ball will fall into bin 1 is x^p/(x^p+y^p), and the probability it lands in bin 2 is y^p/(x^p + y^p). That is, this exponential process is equivalent to the initial balls and bins process.
Now let X = sum X_i and Y = sum Y_i. The infinite sums converge with probability 1 and are unequal with probability 1. So suppose X < Y. Then at some finite "time" in our exponential embedding, bin 1 receives an infinite number of balls while bin 2 just has a finite number of balls, and similarly if Y < X. So eventually, one bin will be the "winner" and take all the remaining balls.
In my mind, that's a beautiful proof.
The setting is balls and bins with feedback: I have two bins, and I'm repeatedly randomly throwing balls into the bins one at at time. When there are x balls in bin 1 and y balls in bin 2, the probability the ball I throw lands in bin 1 is x^p/(x^p+y^p), and the probability it lands in bin 2 is y^p/(x^p + y^p). Initially both bins start with one ball. The goal is to show that when p is greater than 1, at some point, one bin gets all the remaining balls thrown. That is, when there's positive feedback, so the more balls you have the more likely it is that you'll get the next one in a super-linear fashion, eventually the system becomes winner-take-all.
We use the following "exponential embedding". Consider the following process for bin 1. At time 0, we associated an an exponentially distributed random variable X_1 with mean 1 = 1/1^p with the bin. The "time" that bin 1 receives its next ball is X_1. Now it has two balls. We then associate an exponentially distributed random variable X_2 with mean 1/2^p with the bin. And so on.
Do the same thing with bin 2, using random variables Y_1, Y_2, ...
Now, at any point in time, due to the properties of the exponential distribution -- namely, it's memoryless, and the minimum of two exponentials with mean a_1 and a_2 will be the first with probability proportional to 1/a_1 and the second with probability 1/a_2 -- if the loads in the bins are x for bin 1 and y for bin 2, then the next ball will fall into bin 1 is x^p/(x^p+y^p), and the probability it lands in bin 2 is y^p/(x^p + y^p). That is, this exponential process is equivalent to the initial balls and bins process.
Now let X = sum X_i and Y = sum Y_i. The infinite sums converge with probability 1 and are unequal with probability 1. So suppose X < Y. Then at some finite "time" in our exponential embedding, bin 1 receives an infinite number of balls while bin 2 just has a finite number of balls, and similarly if Y < X. So eventually, one bin will be the "winner" and take all the remaining balls.
In my mind, that's a beautiful proof.
Saturday, October 22, 2011
ITCS Review
The list of accepted papers for ITCS (Innovations in Theoretical Computer Science) is up.
Some thoughts:
1) I have expressed reservations in the past about ITCS, based on the idea that it was creating another conference similar to FOCS and STOC, where instead we should be "fixing" FOCS and STOC, for example by expanding it. I suppose my reservations this year are muted. While the titles don't suggest to me that ITCS is necessarily a home for more "innovative" papers than FOCS/STOC, there seems to be no inclination to expand these conferences, so why not have yet another conference where 40 very good papers can go? (Indeed, why not make it a bit larger? I'm not sure how many submissions there were; hopefully someone can confirm, but I'd guess the acceptance rate was roughly 20-25%?)
2) Another issue was ITCS was in China it's first two years, making it seem a bit "exclusive". (Not to Chinese researchers, of course; and not to authors, who were given funds for the trip. But it is a far distance to go for others.) This year, it will be at MIT, which hopefully will attract people from up and down the East Coast (weather permitting), and help it build up a longer term audience.
3) 5 out of the 40 papers have Quantum in the title. Should this be telling us something?
4) Talk I'm most looking forward to: Compressed Matrix Multiplication by Rasmus Pagh. (I've already read and enjoyed the paper.) But I'm also looking forward to seeing Algorithms on Evolving Graphs, if only based on the title.
Some thoughts:
1) I have expressed reservations in the past about ITCS, based on the idea that it was creating another conference similar to FOCS and STOC, where instead we should be "fixing" FOCS and STOC, for example by expanding it. I suppose my reservations this year are muted. While the titles don't suggest to me that ITCS is necessarily a home for more "innovative" papers than FOCS/STOC, there seems to be no inclination to expand these conferences, so why not have yet another conference where 40 very good papers can go? (Indeed, why not make it a bit larger? I'm not sure how many submissions there were; hopefully someone can confirm, but I'd guess the acceptance rate was roughly 20-25%?)
2) Another issue was ITCS was in China it's first two years, making it seem a bit "exclusive". (Not to Chinese researchers, of course; and not to authors, who were given funds for the trip. But it is a far distance to go for others.) This year, it will be at MIT, which hopefully will attract people from up and down the East Coast (weather permitting), and help it build up a longer term audience.
3) 5 out of the 40 papers have Quantum in the title. Should this be telling us something?
4) Talk I'm most looking forward to: Compressed Matrix Multiplication by Rasmus Pagh. (I've already read and enjoyed the paper.) But I'm also looking forward to seeing Algorithms on Evolving Graphs, if only based on the title.
Thursday, October 20, 2011
An Apple a Day
Reviewing papers for a conference is a slow, time-consuming process. Suppose you had 20 reviews due and about 4 weeks to do them. What's your approach?
I take the tortoise approach. I first try to do a quick pass over all the papers to at least have some idea of the topics and themes I'll be dealing with in the papers. This lets me find papers that, at least on a fast first reading, seem unusually good or unusually bad, and lets me see if any papers are sufficiently related that they should be compared to each other implicitly or explicitly when I do my reviews. But then, I try to set aside time to do one review a day, more or less. I'll enter the review, press the button, and put it up for others to see. I won't go back and revise things until the first round is over unless another paper I'm reading or another review I see makes me rethink substantially. At the end, I'll go back and check that my scores seem consistent, given that I've seen my full set of papers. Slow forward progress, with an eventual finish line.
Doing a paper a day does mean I limit the time I put into each review. While there's some variance, I almost never let myself go down a rabbit hole with a paper. That's not always a good thing; sometimes, finding a bug in a proof or a similar serious flaw in a paper takes several hours of careful thought, and unless I pick up that's there a problem right away, I often miss it while going on to the next review. (This is just one good reason for why we have multiple reviewers!)
Perhaps another reason this is not always a good strategy: I'm told it's noticed that my reviews are actually done on time, and apparently this leads to people asking me to be on PCs.
I take the tortoise approach. I first try to do a quick pass over all the papers to at least have some idea of the topics and themes I'll be dealing with in the papers. This lets me find papers that, at least on a fast first reading, seem unusually good or unusually bad, and lets me see if any papers are sufficiently related that they should be compared to each other implicitly or explicitly when I do my reviews. But then, I try to set aside time to do one review a day, more or less. I'll enter the review, press the button, and put it up for others to see. I won't go back and revise things until the first round is over unless another paper I'm reading or another review I see makes me rethink substantially. At the end, I'll go back and check that my scores seem consistent, given that I've seen my full set of papers. Slow forward progress, with an eventual finish line.
Doing a paper a day does mean I limit the time I put into each review. While there's some variance, I almost never let myself go down a rabbit hole with a paper. That's not always a good thing; sometimes, finding a bug in a proof or a similar serious flaw in a paper takes several hours of careful thought, and unless I pick up that's there a problem right away, I often miss it while going on to the next review. (This is just one good reason for why we have multiple reviewers!)
Perhaps another reason this is not always a good strategy: I'm told it's noticed that my reviews are actually done on time, and apparently this leads to people asking me to be on PCs.
Tuesday, October 18, 2011
John Byers on WBUR
Listening to my co-author, John Byers, streamed live on WBUR, discussing our work on Groupon. Ben Edelman is another participant in the show.
Here's the link.
Here's the link.
Wednesday, October 12, 2011
Listen
A colleague outside theory (but inside computer science) recently brought up an interesting question with me that seemed like a possible research-level issue. We had some back and forth, trying to figure out what we each meant (naturally, our "vocabularies" are a bit different in how we describe the problem), what the actual question was, and if there was a direction to go. After a couple of rounds of this, he thanked me. Paraphrasing: "I appreciate your patience. My experience is other theorists are often immediately dismissive to these sorts of questions."
I was taken aback. First, I'm not sure patient is a word commonly used to describe me. Second, this colleague is a first-rate genius (with the track record to prove it). Who wouldn't listen to what they have to say? Quite frankly, I was happy they were interested in talking to me!
But it's been gnawing at me. If a high-powered colleague outside theory has this impression of theory and theorists, how do we appear to others? Was this an isolated opinion, or a common feeling?
I know 20 years ago, back when I was in graduate school, the theory/systems divide was quite large, at least at Berkeley. There seemed to be minimal communication among the faculty groups. Indeed, in part that was one reason that, at the time, the LogP paper seemed like such a big deal; Dick Karp had successfully crossed over and worked with the systems side to build a model for parallel computation! It was, sadly, notable, if only because such collaborative work had seemed so rare.
I've generally felt that while this theory/systems divide was still much larger than I might personally like that there had been a lot of progress since my grad student days. I feel I can point to a significant number of examples. But perhaps I'm holding the unusual opinion. Maybe there's still not enough listening going on, in at least one direction.
I was taken aback. First, I'm not sure patient is a word commonly used to describe me. Second, this colleague is a first-rate genius (with the track record to prove it). Who wouldn't listen to what they have to say? Quite frankly, I was happy they were interested in talking to me!
But it's been gnawing at me. If a high-powered colleague outside theory has this impression of theory and theorists, how do we appear to others? Was this an isolated opinion, or a common feeling?
I know 20 years ago, back when I was in graduate school, the theory/systems divide was quite large, at least at Berkeley. There seemed to be minimal communication among the faculty groups. Indeed, in part that was one reason that, at the time, the LogP paper seemed like such a big deal; Dick Karp had successfully crossed over and worked with the systems side to build a model for parallel computation! It was, sadly, notable, if only because such collaborative work had seemed so rare.
I've generally felt that while this theory/systems divide was still much larger than I might personally like that there had been a lot of progress since my grad student days. I feel I can point to a significant number of examples. But perhaps I'm holding the unusual opinion. Maybe there's still not enough listening going on, in at least one direction.
Monday, October 10, 2011
Reading Confidence Men
My current spare time reading* is Confidence Men , Ron Suskind's book on Wall Street and the Presidency. Without "taking sides" with regard to Larry Summers, I have to admit enjoying reading this paragraph:
, Ron Suskind's book on Wall Street and the Presidency. Without "taking sides" with regard to Larry Summers, I have to admit enjoying reading this paragraph:
"It all boils down to the classic Larry Summers problem: he can frame arguments with such force and conviction that people think he knows more than he does. Instead of looking at a record pockmarked with bad decisions, people see his extemporaneous brilliance and let themselves be dazzled. Summers's long career has come to look, more and more, like one long demonstration of the difference between wisdom and smarts."
In Summers's defense(?), there are lots of people who would fit this description...
* As a parent who tries to read what my kids are reading, my future spare time reading looks to be the similarly political but less timely Mockingjay and the new-to-me series Artemis Fowl
and the new-to-me series Artemis Fowl . Recommendations for 8-10 year-old readings welcome.
. Recommendations for 8-10 year-old readings welcome.
"It all boils down to the classic Larry Summers problem: he can frame arguments with such force and conviction that people think he knows more than he does. Instead of looking at a record pockmarked with bad decisions, people see his extemporaneous brilliance and let themselves be dazzled. Summers's long career has come to look, more and more, like one long demonstration of the difference between wisdom and smarts."
In Summers's defense(?), there are lots of people who would fit this description...
* As a parent who tries to read what my kids are reading, my future spare time reading looks to be the similarly political but less timely Mockingjay
Sunday, October 09, 2011
Submissions, A Comparison
I just got my set of NSDI papers to review, and have been looking them over.
One thing that immediately strikes me as I give them a first quick pass is how nice it is that the submissions are 14 double-column pages. The authors have space to present a meaningful introduction and a reasonably full description of and comparison with related work. They can include (detailed) pseudocode as well as description of their algorithms. They have space for a full page (or more) of graphs for their experimental results, and even more space to actually explain them. The papers actually make sense, in that they're written in sequential order without having to flip over to "appendices" to find results. The phrase "this will appear in the full paper" appears rarely -- not at all in most papers. The papers are, as a consequence, a pleasure to read. (Well, I can't vouch for the actual content yet, but you get what I mean.)
As a reviewer, it's also nice that if I tell the authors they've left out something that I think is important, I'll generally have confidence they'll have space to put it in if the paper is accepted, and that it's a reasonable complaint to make, in that they ostensibly had space to cover my issue. (There are some papers which fill the 14 pages and perhaps won't have something obvious that could be removed, but experience suggests they'll be rare.)
So I wonder again why theory conferences have 10-page single-column submission formats ("appendices allowed"!), or, even worse, for conferences like ICALP and ESA, they have final page counts of 10-12 pages in the over-1/2-blank-page LNCS format. (Really, it's just about enough space for an abstract, introduction, and pointer to your arxiv version.) Interestingly, for my accepted SODA papers this year -- which went with 10 page submissions, "full versions" attached on the back, but had 20 pages for accepted papers -- both sets of co-authors didn't want to bother when the final submission deadline came around to filling the 20 pages, figuring people could just be pointed to the arxiv (or eventual final journal) version. Why create yet another version of the paper according to arbitrary page limitations? I certainly couldn't suggest a good reason.
On the theory side, as I've maintained for years, we're doing something wrong with our submissions, with artificial page limits creating more mindless work for authors and making decisions more arbitrary than they need to be.
One thing that immediately strikes me as I give them a first quick pass is how nice it is that the submissions are 14 double-column pages. The authors have space to present a meaningful introduction and a reasonably full description of and comparison with related work. They can include (detailed) pseudocode as well as description of their algorithms. They have space for a full page (or more) of graphs for their experimental results, and even more space to actually explain them. The papers actually make sense, in that they're written in sequential order without having to flip over to "appendices" to find results. The phrase "this will appear in the full paper" appears rarely -- not at all in most papers. The papers are, as a consequence, a pleasure to read. (Well, I can't vouch for the actual content yet, but you get what I mean.)
As a reviewer, it's also nice that if I tell the authors they've left out something that I think is important, I'll generally have confidence they'll have space to put it in if the paper is accepted, and that it's a reasonable complaint to make, in that they ostensibly had space to cover my issue. (There are some papers which fill the 14 pages and perhaps won't have something obvious that could be removed, but experience suggests they'll be rare.)
So I wonder again why theory conferences have 10-page single-column submission formats ("appendices allowed"!), or, even worse, for conferences like ICALP and ESA, they have final page counts of 10-12 pages in the over-1/2-blank-page LNCS format. (Really, it's just about enough space for an abstract, introduction, and pointer to your arxiv version.) Interestingly, for my accepted SODA papers this year -- which went with 10 page submissions, "full versions" attached on the back, but had 20 pages for accepted papers -- both sets of co-authors didn't want to bother when the final submission deadline came around to filling the 20 pages, figuring people could just be pointed to the arxiv (or eventual final journal) version. Why create yet another version of the paper according to arbitrary page limitations? I certainly couldn't suggest a good reason.
On the theory side, as I've maintained for years, we're doing something wrong with our submissions, with artificial page limits creating more mindless work for authors and making decisions more arbitrary than they need to be.
Thursday, October 06, 2011
Goodbye to Steve Jobs
My Mac laptop froze today. It was an unusual occurrence; I turned the machine off, and for a minute it wouldn't turn back on again. I was in a panic.
Then it went back to normal.
After the fact, I was wondering if my machine was having its own minute of silence. Then I had the morbid idea -- what if Steve Jobs had the power to arrange for all Mac products and iProducts to stop working when he died? It would be a disaster for so many of us -- not just the loss of individual data, but the loss of the platforms and devices he made reality, that so many of us use and love.
Steve Jobs may be gone, but his legacy lives on.
Then it went back to normal.
After the fact, I was wondering if my machine was having its own minute of silence. Then I had the morbid idea -- what if Steve Jobs had the power to arrange for all Mac products and iProducts to stop working when he died? It would be a disaster for so many of us -- not just the loss of individual data, but the loss of the platforms and devices he made reality, that so many of us use and love.
Steve Jobs may be gone, but his legacy lives on.
Saturday, October 01, 2011
New York Times
Our work on daily deals is mentioned and linked to in Sunday's New York Times (front page). (John Byers even got a quote in!) It was also mentioned in this week's print edition of Time magazine. (Behind a paywall, so here's a jpeg.)
Sadly, the name Mitzenmacher doesn't appear on these items. ("...researchers from Boston University and Harvard..." seems to be a common phrase), so I continue to toil happily in relative obscurity.
My brother points out that this is all just an example of why print media is disappearing. He says most anyone who might have seriously cared about our work would have heard about it two weeks ago on the Internet. The print media is just getting to it now? They're two weeks behind.
{kind=link}
Sadly, the name Mitzenmacher doesn't appear on these items. ("...researchers from Boston University and Harvard..." seems to be a common phrase), so I continue to toil happily in relative obscurity.
My brother points out that this is all just an example of why print media is disappearing. He says most anyone who might have seriously cared about our work would have heard about it two weeks ago on the Internet. The print media is just getting to it now? They're two weeks behind.
Thursday, September 29, 2011
Allerton Part 2 : Venue Change?
Yesterday, I thought the best talks I saw were by Devavrat Shah and Dina Katabi.
Dev was talking about how to track where rumors start. The model is you have a graph of nodes that have been infected (by a rumor, or disease, or whatever), and based on the the shape of that graph, you want to figure out where the process started. To get a picture of what I mean, suppose you were looking at a grid graph, and the infected area looked roughly like a circle. You'd expect the infection started somewhere near the middle of the circle. They've placed this in a mathematical framework (a distribution for the time to cross an edge, starting with tree graphs, etc.) that allows for analyzing these sorts of processes. This seems to be the arxiv version of the work.
Dina talked about 802.11n+, which they describe as "a fully distributed random access protocol for MIMO networks. 802.11n+ allows nodes that differ in the number of antennas to contend not just for time, but also for the degrees of freedom provided by multiple antennas." By making use of nulling and alignment, they can extend 802.11 so that instead of competing for time slots, multiple antenna systems can compete for degrees of freedom within a time slot, allowing those devices with multiple antennas to take full advantage (and in particular allowing them to overlap transmissions with devices with fewer antennas). I would have heard about it earlier, I guess, if I had gone to SIGCOMM this year. The project page is here.
There's a whole session this morning on "mean field analysis" and games. Mean field analysis (in my loose interpretation) means pretend your system gets big and turn it into a differential equation -- apparently a useful way to tackle various large-scale distributed agent/learning systems. It's what I used to study load-balancing systems way back for my thesis (and still find an occasional uses for today). Interesting to see it used for another set of problems. Ramesh Johari's student (I didn't catch which one) gave a talk on a really interesting model of dynamic auctions with learning where you could gain some real insight using a mean-field analysis. (How much should agents in an auction "overbid" when they're learning their value for winning an auction? It depends on how much they think they'll gain in the future based on what they learn about their true value.) This seems to be a preliminary version of the work.
Now for the "negative" -- something I'm going to suggest to the Allerton folks. It's time, I think, to find a different location. The Allerton conference center is very beautiful, but it's not suitable, in many respects, for this event any more. I was told there were about 330 registered attendees from outside UIUC, plus an additional 120 or so from UIUC. It's a bit hard to turn that into a true count; many (most?) UIUC people probably drop by 1 day, most attendees probably 1.5-2 days of the three. But Allerton really wasn't designed for a crowd that large. If you're not in one of the "big rooms", and people want to come to your talk, many times they can't get in. For example, the social network session was remarkably popular; the room could seat 40 people, and there were about 20+ people crowded around and outside the doorway -- which was not only not ideal, but it was also disruptive, as the open door meant a lot of noise in the room. Actually, the acoustics aren't particularly good in any of the rooms, even the big ones. Attendance in the early am is very low, in part I think because people staying "in town" have a non-trivial drive to get to Allerton.
When the event was smaller, like 200-250 people, everyone coped with these problems. It's really not working now.
I can understand there's an attachment to the Allerton center -- and how could it be the "Allerton conference" (next year is it's 50th year!) if it wasn't at Allerton? But this has been an issue for years, and only seems to get worse. There must be a conference venue on or near UIUC campus that would work as well -- at the very least, my opinion is it's time to look....
And now, back to the airport...
Dev was talking about how to track where rumors start. The model is you have a graph of nodes that have been infected (by a rumor, or disease, or whatever), and based on the the shape of that graph, you want to figure out where the process started. To get a picture of what I mean, suppose you were looking at a grid graph, and the infected area looked roughly like a circle. You'd expect the infection started somewhere near the middle of the circle. They've placed this in a mathematical framework (a distribution for the time to cross an edge, starting with tree graphs, etc.) that allows for analyzing these sorts of processes. This seems to be the arxiv version of the work.
Dina talked about 802.11n+, which they describe as "a fully distributed random access protocol for MIMO networks. 802.11n+ allows nodes that differ in the number of antennas to contend not just for time, but also for the degrees of freedom provided by multiple antennas." By making use of nulling and alignment, they can extend 802.11 so that instead of competing for time slots, multiple antenna systems can compete for degrees of freedom within a time slot, allowing those devices with multiple antennas to take full advantage (and in particular allowing them to overlap transmissions with devices with fewer antennas). I would have heard about it earlier, I guess, if I had gone to SIGCOMM this year. The project page is here.
There's a whole session this morning on "mean field analysis" and games. Mean field analysis (in my loose interpretation) means pretend your system gets big and turn it into a differential equation -- apparently a useful way to tackle various large-scale distributed agent/learning systems. It's what I used to study load-balancing systems way back for my thesis (and still find an occasional uses for today). Interesting to see it used for another set of problems. Ramesh Johari's student (I didn't catch which one) gave a talk on a really interesting model of dynamic auctions with learning where you could gain some real insight using a mean-field analysis. (How much should agents in an auction "overbid" when they're learning their value for winning an auction? It depends on how much they think they'll gain in the future based on what they learn about their true value.) This seems to be a preliminary version of the work.
Now for the "negative" -- something I'm going to suggest to the Allerton folks. It's time, I think, to find a different location. The Allerton conference center is very beautiful, but it's not suitable, in many respects, for this event any more. I was told there were about 330 registered attendees from outside UIUC, plus an additional 120 or so from UIUC. It's a bit hard to turn that into a true count; many (most?) UIUC people probably drop by 1 day, most attendees probably 1.5-2 days of the three. But Allerton really wasn't designed for a crowd that large. If you're not in one of the "big rooms", and people want to come to your talk, many times they can't get in. For example, the social network session was remarkably popular; the room could seat 40 people, and there were about 20+ people crowded around and outside the doorway -- which was not only not ideal, but it was also disruptive, as the open door meant a lot of noise in the room. Actually, the acoustics aren't particularly good in any of the rooms, even the big ones. Attendance in the early am is very low, in part I think because people staying "in town" have a non-trivial drive to get to Allerton.
When the event was smaller, like 200-250 people, everyone coped with these problems. It's really not working now.
I can understand there's an attachment to the Allerton center -- and how could it be the "Allerton conference" (next year is it's 50th year!) if it wasn't at Allerton? But this has been an issue for years, and only seems to get worse. There must be a conference venue on or near UIUC campus that would work as well -- at the very least, my opinion is it's time to look....
And now, back to the airport...
Wednesday, September 28, 2011
Allerton 2011
I woke up at an absurdly early hour this morning to get on a plane and go to the Allerton conference. I'm giving a talk this afternoon on Invertible Bloom Lookup Tables (arxiv link) (joint work with Michael Goodrich). It's a "lookup table", not a Bloom filter, because you want to be able to store key-value pairs; you query for a key, and get back a value. It's invertible, because besides being able to do lookups, you can "invert" the data structure and get back all the key-value pairs it contains (with high probability, assuming you haven't overloaded the structure). This paper is really on the theory, but if you want to see a cool use for IBLTs, there's a paper by Eppstein, Goodrich, Uyeda, and Varghese from this year's SIGCOMM (Efficient Set Reconciliation) with a compelling application.
Allerton is a different sort of conference, as I've discussed before (like here and here, among others). A mix of invited and submitted papers, a wide diversity of topics, lots of parallel sessions. It seems absurdly crowded this year -- I had to park in the ancillary parking because the lot was full, and the rooms where the talks are held all seem to be bursting. (The conference, unfortunately, really has outgrown the space where the conference is held.) I'm guessing well over 300 registered; I'll have to check. The conference gives me a chance to catch up with colleagues who are more on the EE/networking side; I've seen other CS theorists here in years past, but I haven't noticed anyone yet.
If you're here, maybe come by my talk this afternoon, or say hi if you see me hanging around.
Allerton is a different sort of conference, as I've discussed before (like here and here, among others). A mix of invited and submitted papers, a wide diversity of topics, lots of parallel sessions. It seems absurdly crowded this year -- I had to park in the ancillary parking because the lot was full, and the rooms where the talks are held all seem to be bursting. (The conference, unfortunately, really has outgrown the space where the conference is held.) I'm guessing well over 300 registered; I'll have to check. The conference gives me a chance to catch up with colleagues who are more on the EE/networking side; I've seen other CS theorists here in years past, but I haven't noticed anyone yet.
If you're here, maybe come by my talk this afternoon, or say hi if you see me hanging around.
Tuesday, September 27, 2011
Set Competition
As an applied probability exercise, I had my class compute empirically the probability of a game failing on the nth round for the game of Set. (See my previous post about this; here failure means there's no set on the nth round, and they were asked to implement the "choose a random set" strategy if there was more than one.) They were also supposed to try to calculate the probability of using all 81 cards in sets through the course of the game -- what we might call a perfect game.
Some students explored a bit and noted that changing from the random strategy could significantly increase the probability of a perfect game. So I think the next time I decide to use this assignment, I'll turn it into a competition. Students will have to develop a strategy that maximizes the probability of achieving a perfect game. Prizes will go to the best strategy (which hopefully could be easily determined after a few billion runs or so -- I suppose I'll have to introduce some sort of computational limits on the strategy to ensure that many runs can be done in a suitable time frame), and the best "succinct" strategy -- that is, the best strategy that can be described in English in at most a few reasonable sentences.
It's also interesting to think about optimal strategies in the offline case, where the permutation determining how the cards will be dealt out is given in advance. I keep thinking maybe there's a way to effectively calculate whether a perfect game can be found for a given permutation, and then thinking there can't be. (Though, admittedly, I haven't thought a lot yet.) So maybe it makes sense to run the competition for both the online and offline versions of the problem.
Some students explored a bit and noted that changing from the random strategy could significantly increase the probability of a perfect game. So I think the next time I decide to use this assignment, I'll turn it into a competition. Students will have to develop a strategy that maximizes the probability of achieving a perfect game. Prizes will go to the best strategy (which hopefully could be easily determined after a few billion runs or so -- I suppose I'll have to introduce some sort of computational limits on the strategy to ensure that many runs can be done in a suitable time frame), and the best "succinct" strategy -- that is, the best strategy that can be described in English in at most a few reasonable sentences.
It's also interesting to think about optimal strategies in the offline case, where the permutation determining how the cards will be dealt out is given in advance. I keep thinking maybe there's a way to effectively calculate whether a perfect game can be found for a given permutation, and then thinking there can't be. (Though, admittedly, I haven't thought a lot yet.) So maybe it makes sense to run the competition for both the online and offline versions of the problem.
Wednesday, September 21, 2011
Beyond Worst Case Analysis Workshop
I'm just off a plane coming home from the Beyond Worst Case Analysis Workshop at Stanford. It went really well, and I really enjoyed it.
I think a variety of things made it work. First, and I apologize to Tim Roughgarden for saying it, but the execution was superb -- someone should make him organize more things. Great room, great food, great staff on hand (thanks to Lynda Harris for being incredibly helpful), and a great collection of speakers. Also, an excellent location. Stanford is relatively easy to get to with 2 major airports nearby (but avoid the cabs -- it's now over $100 to take a cab from SFO!), and the location guarantees an audience of Stanford, Microsoft, and Google folks. (While not everyone was there all the time, I understand well over 100 people were registered.)
To the content. It was a great program -- apparently the talks will be on the web later, so you may want to check them out if you weren't there. My favorites would have to be Dan Spielman's talk on smoothed analysis (perhaps because Dan just always gives great talks), and Kevin Leyton-Brown's talk on statistical methods (using learning theory) to predict an algorithm's performance on new instances. (Can you predict the running time of your satisfiability algorithm accurately before running it on a specific instance very quickly just by taking a careful look at the problem? The answer seems to be -- yes you can!)
There was a panel that focused on questions like "Where could we point students to work on these sorts of problems. What are the currently most glaring examples of algorithms whose properties are poorly explained by existing theoretical models, where there might be hope for progress?" and "To what extent can "real-world data" be modeled? Is it important to model accurately the properties of "real-world data"?" While the panel ended up being fairly uncontroversial -- I'm afraid no fights or even major disagreement broke out -- I found it very interesting to listen to the others on the panel give their opinions and insights on these questions.
I think people got into the spirit of the workshop. Kevin, an AI person by trade, found it amazing that theorists were getting together to talk about heuristics and experiments. (Kevin's talk was followed by Dick Karp talking about his work on tuning and validating heuristic algorithms -- though of course not all talks were on that theme.) It will be interesting to see if this workshop inspires any specific new research -- but even if not, it was well organized, well put together for content, and well worth the trip.
My talk slides are here.
I think a variety of things made it work. First, and I apologize to Tim Roughgarden for saying it, but the execution was superb -- someone should make him organize more things. Great room, great food, great staff on hand (thanks to Lynda Harris for being incredibly helpful), and a great collection of speakers. Also, an excellent location. Stanford is relatively easy to get to with 2 major airports nearby (but avoid the cabs -- it's now over $100 to take a cab from SFO!), and the location guarantees an audience of Stanford, Microsoft, and Google folks. (While not everyone was there all the time, I understand well over 100 people were registered.)
To the content. It was a great program -- apparently the talks will be on the web later, so you may want to check them out if you weren't there. My favorites would have to be Dan Spielman's talk on smoothed analysis (perhaps because Dan just always gives great talks), and Kevin Leyton-Brown's talk on statistical methods (using learning theory) to predict an algorithm's performance on new instances. (Can you predict the running time of your satisfiability algorithm accurately before running it on a specific instance very quickly just by taking a careful look at the problem? The answer seems to be -- yes you can!)
There was a panel that focused on questions like "Where could we point students to work on these sorts of problems. What are the currently most glaring examples of algorithms whose properties are poorly explained by existing theoretical models, where there might be hope for progress?" and "To what extent can "real-world data" be modeled? Is it important to model accurately the properties of "real-world data"?" While the panel ended up being fairly uncontroversial -- I'm afraid no fights or even major disagreement broke out -- I found it very interesting to listen to the others on the panel give their opinions and insights on these questions.
I think people got into the spirit of the workshop. Kevin, an AI person by trade, found it amazing that theorists were getting together to talk about heuristics and experiments. (Kevin's talk was followed by Dick Karp talking about his work on tuning and validating heuristic algorithms -- though of course not all talks were on that theme.) It will be interesting to see if this workshop inspires any specific new research -- but even if not, it was well organized, well put together for content, and well worth the trip.
My talk slides are here.
Tuesday, September 20, 2011
Guest Post on NYCE (Giorgos Zervas)
GUEST POST by GIORGOS ZERVAS
I was at NYCE 2011 this past Friday. It was a thoroughly enjoyable and productive experience. I feel like I got a conference's worth for the cost of and time commitment of a long commute.
The day started with three hour-long plenary talks, followed by lunch and a poster session, followed by an hour of 10 minute talks, and concluded with two more plenary talks. (And all of that for about $20.)
It turns out a lot can be squeezed into 10 minutes. Halfway into the first speaker's talk, with 5 minutes left on the clock, I was almost convinced he was running out of time. Everyone worked great around the time constraint to succinctly deliver their talks.
The plenary talk roster was varied and exciting (at least by one other account). I particularly enjoyed Jonathan Levin's talk on eBay experiments (pdf of the paper) in part because I was least familiar with it, and in part because I think I can use his key method. Here's the gist: instead of relying on random observations look for experiments that have been conducted on your behalf by market participants. To use his eBay example, auctions have a bunch of parameters: the item, its starting price, its reserve price, and so on. Quite often it turns out you can find sets of auctions ("experiments") that are identical in all but one parameter. This allows you to directly quantify the effect of the varying parameter. To say I wish I'd thought of this is an understatement -- I am trying to convince myself that I actually didn't. (I didn't.)
Of interest -- likely to myself only -- was the passing mention of Swoopo in two plenary talks. Their sudden demise still puzzles me. While writing our Swoopo paper they were running about 200 auctions a day. A few months after EC'10 when I checked again they were running about one hundred. They were responding to reduced demand but why were "entertainment shoppers" driven away? The business model certainly did not die as others have successfully taken Swoopo's place. One possibility is that the barrier to entry in this type business is low. Around Swoopo's peak there were people making money off penny-auction scripts they'd sell for a few hundred bucks. Hundreds of clones sprung. Buy a script and some hosting, run auctions, and ship directly from Amazon. In an interesting parallel the daily deals business also seems to have a very low barrier to entry judging from the hundreds of Groupon clones. I am still kicking myself for stopping data collection after our Swoopo paper was done.
I was at NYCE 2011 this past Friday. It was a thoroughly enjoyable and productive experience. I feel like I got a conference's worth for the cost of and time commitment of a long commute.
The day started with three hour-long plenary talks, followed by lunch and a poster session, followed by an hour of 10 minute talks, and concluded with two more plenary talks. (And all of that for about $20.)
It turns out a lot can be squeezed into 10 minutes. Halfway into the first speaker's talk, with 5 minutes left on the clock, I was almost convinced he was running out of time. Everyone worked great around the time constraint to succinctly deliver their talks.
The plenary talk roster was varied and exciting (at least by one other account). I particularly enjoyed Jonathan Levin's talk on eBay experiments (pdf of the paper) in part because I was least familiar with it, and in part because I think I can use his key method. Here's the gist: instead of relying on random observations look for experiments that have been conducted on your behalf by market participants. To use his eBay example, auctions have a bunch of parameters: the item, its starting price, its reserve price, and so on. Quite often it turns out you can find sets of auctions ("experiments") that are identical in all but one parameter. This allows you to directly quantify the effect of the varying parameter. To say I wish I'd thought of this is an understatement -- I am trying to convince myself that I actually didn't. (I didn't.)
Of interest -- likely to myself only -- was the passing mention of Swoopo in two plenary talks. Their sudden demise still puzzles me. While writing our Swoopo paper they were running about 200 auctions a day. A few months after EC'10 when I checked again they were running about one hundred. They were responding to reduced demand but why were "entertainment shoppers" driven away? The business model certainly did not die as others have successfully taken Swoopo's place. One possibility is that the barrier to entry in this type business is low. Around Swoopo's peak there were people making money off penny-auction scripts they'd sell for a few hundred bucks. Hundreds of clones sprung. Buy a script and some hosting, run auctions, and ship directly from Amazon. In an interesting parallel the daily deals business also seems to have a very low barrier to entry judging from the hundreds of Groupon clones. I am still kicking myself for stopping data collection after our Swoopo paper was done.
Back to NYCE itself, if there is one thing I'd maybe have wanted to see more of is student talks (especially of the 10 minute variety). I guess the poster session made up for this but as someone with a poster to present I didn't have to chance to walk around and see others'. Which reminds me, thanks to everyone who stopped by my poster, and to the organizers for putting everything together!
Friday, September 16, 2011
Travels and Teaching
I'll be at the Beyond Worst Case Analysis workshop next week, and Allerton the week after. For each, I'll have to miss a class. I also have some other travels that may involve missing classes this semester as well -- I'll be missing more class than usual this semester, but they're for good reasons.
I'll have Justin and Giorgos cover a lecture for me (thanks, guys!), but next week I'm doing an experiment: I'm substituting videos for my class. I've pointed them to 2005 MSRI workshop Models of Real-World Random Networks, and having them watch some talks. One is my survey talk on power laws, so it's still "me" teaching, but then I have a few impressive "guest lecturers" from the workshop to cover the rest; all the talks focus on power laws in some way. I've even put together an "in-class" exercise for them to do on the subject -- out of class, of course.
I wonder if this is a good approach or not. I'll have to ask the students. It's not ideal, but either is cancelling class. Has anyone else started using videos as a solution to the missed lecture problem? Are there ways to make it a more useful experience?
By the way, looking back, that 2005 MSRI workshop had a bunch of interesting talks. Worth checking out sometime if you're interested in the area. I looked younger then.
Reminder : Giorgos has a poster at the New York Computer Science and Economics Day today. Go check it out!
I'll have Justin and Giorgos cover a lecture for me (thanks, guys!), but next week I'm doing an experiment: I'm substituting videos for my class. I've pointed them to 2005 MSRI workshop Models of Real-World Random Networks, and having them watch some talks. One is my survey talk on power laws, so it's still "me" teaching, but then I have a few impressive "guest lecturers" from the workshop to cover the rest; all the talks focus on power laws in some way. I've even put together an "in-class" exercise for them to do on the subject -- out of class, of course.
I wonder if this is a good approach or not. I'll have to ask the students. It's not ideal, but either is cancelling class. Has anyone else started using videos as a solution to the missed lecture problem? Are there ways to make it a more useful experience?
By the way, looking back, that 2005 MSRI workshop had a bunch of interesting talks. Worth checking out sometime if you're interested in the area. I looked younger then.
Reminder : Giorgos has a poster at the New York Computer Science and Economics Day today. Go check it out!
Thursday, September 15, 2011
This Week, I Am Part of an Internet Meme
My frequent co-authors John Byers, Giorgos Zervas, and I posted an extended version of a current submission to the arxiv (as people do), which showed up last Friday or thereabouts. Daily Deals: Prediction, Social Diffusion, and Reputational Ramifications discusses some analysis we did on daily deal sites (Groupon, LivingSocial), including interactions between daily deal sites and social network sites (Facebook, Yelp).
The work got a plug Monday on the MIT Technology Review. They naturally focused on our most "controversial" finding, and I quote them:
"A Groupon deal might boost sales but, it can also lower a merchant's reputation as measured by Yelp ratings, say computer scientists who have analyzed the link between daily deals and online reviews."
Apparently, many people are interested in statements of that form, especially business types, and that's where the fun started. We got some e-mails from people who work for firms that use statistical analyses in planning marketing efforts who had seen the article (and wanted our not-yet-released data set). We noticed the review article was getting tweeted. We started tracking a tweet feed to find out where else it was showing up. (As a very partial list, Business Insider, Chicago Tribune, The Independent, Search Engine Journal.) Monday we were worried that people might try to actually call us up and talk with us, but fortunately, that hasn't happened. Instead of feeling pressured, we've just been able to enjoy watching.
It's amusing to see how these things spread through the Internet. A lot of sites are just cutting and pasting from the MIT Tech Review. I know this because, in what I personally find to be the most amusing of mistakes, they refer to Giorgos as "Georgia Zervas". Giorgos does seem to have multiple name spellings (he also uses Georgios), but Georgia is not quite right. (It is, however, my new nickname for him*.) Georgia Zervas, according to Google, has popped up almost 200 times in the last 3 days.
We weren't really expecting this. I think part of the reason we didn't expect much reaction is pre-summer we put up a placeholder with some initial data: A Month in the Life of Groupon. This didn't seem to get much notice. Indeed, we had submitted it to NetEcon, and were essentially told by reviewers the paper was too boring. I must admit I disagreed, then and now, with the reviewers. But, to be fair, that version of the paper didn't contain the data sets and analysis for LivingSocial, the Facebook Likes, and the Yelp reviews; it just had Groupon data (though we made clear this was an "appetizer" and more was to come). John actually completely disagrees with me. I quote: "For the record, I agree with the NetEcon reject decision. They should be applauded for making us do more work." My take was the bar for a workshop paper was too high if this wasn't sufficiently interesting. Giorgos wonders if by John's logic we're hoping the paper gets rejected again.
Also, we didn't get nearly the same sort of attention for our previous similar-in-spirit work analyzing penny auction sites like Swoopo (entitled Information Asymmetries in Pay-Per-Bid Auctions: How Swoopo Makes Bank). Daily deal sites are MUCH bigger, and I suppose the results for Swoopo are a bit harder to summarize for mass consumption.
Anyhow, Giorgos will be at the New York Computer Science and Economics Day this Friday with a poster on the subject. Stop by and talk with him! (Giorgos recently completed his PhD at BU, and is doing a Simons postdoctoral fellowship with Joan Feigenbaum, while also hanging out some with me at Harvard as an affiliate of our Center for Research on Computation and Society.)
* Don't worry Giorgos. I'm kidding. Sort of.
The work got a plug Monday on the MIT Technology Review. They naturally focused on our most "controversial" finding, and I quote them:
"A Groupon deal might boost sales but, it can also lower a merchant's reputation as measured by Yelp ratings, say computer scientists who have analyzed the link between daily deals and online reviews."
Apparently, many people are interested in statements of that form, especially business types, and that's where the fun started. We got some e-mails from people who work for firms that use statistical analyses in planning marketing efforts who had seen the article (and wanted our not-yet-released data set). We noticed the review article was getting tweeted. We started tracking a tweet feed to find out where else it was showing up. (As a very partial list, Business Insider, Chicago Tribune, The Independent, Search Engine Journal.) Monday we were worried that people might try to actually call us up and talk with us, but fortunately, that hasn't happened. Instead of feeling pressured, we've just been able to enjoy watching.
It's amusing to see how these things spread through the Internet. A lot of sites are just cutting and pasting from the MIT Tech Review. I know this because, in what I personally find to be the most amusing of mistakes, they refer to Giorgos as "Georgia Zervas". Giorgos does seem to have multiple name spellings (he also uses Georgios), but Georgia is not quite right. (It is, however, my new nickname for him*.) Georgia Zervas, according to Google, has popped up almost 200 times in the last 3 days.
We weren't really expecting this. I think part of the reason we didn't expect much reaction is pre-summer we put up a placeholder with some initial data: A Month in the Life of Groupon. This didn't seem to get much notice. Indeed, we had submitted it to NetEcon, and were essentially told by reviewers the paper was too boring. I must admit I disagreed, then and now, with the reviewers. But, to be fair, that version of the paper didn't contain the data sets and analysis for LivingSocial, the Facebook Likes, and the Yelp reviews; it just had Groupon data (though we made clear this was an "appetizer" and more was to come). John actually completely disagrees with me. I quote: "For the record, I agree with the NetEcon reject decision. They should be applauded for making us do more work." My take was the bar for a workshop paper was too high if this wasn't sufficiently interesting. Giorgos wonders if by John's logic we're hoping the paper gets rejected again.
Also, we didn't get nearly the same sort of attention for our previous similar-in-spirit work analyzing penny auction sites like Swoopo (entitled Information Asymmetries in Pay-Per-Bid Auctions: How Swoopo Makes Bank). Daily deal sites are MUCH bigger, and I suppose the results for Swoopo are a bit harder to summarize for mass consumption.
Anyhow, Giorgos will be at the New York Computer Science and Economics Day this Friday with a poster on the subject. Stop by and talk with him! (Giorgos recently completed his PhD at BU, and is doing a Simons postdoctoral fellowship with Joan Feigenbaum, while also hanging out some with me at Harvard as an affiliate of our Center for Research on Computation and Society.)
* Don't worry Giorgos. I'm kidding. Sort of.
Wednesday, September 14, 2011
SODA Accepts -- The Count
People in various have been noting the SODA accepts, but nobody has been talking about the numbers. I count 138 papers accepted. I can't find now how many submissions there were; I recall it was over 600 abstracts, but I think it cut down to 520-540 or so. So this seems like just over 25%.
Is that a good number? Too many? Too few?
I admit, I have trouble believing that there weren't at least 40, 50, maybe 100 of those rejected submitted papers that were of sufficient quality that it would have been just fine to have them in. I could be wrong -- I wasn't on the committee -- but I'd guess there was more good stuff out there.
For those papers that were rejected, where will they go? ICALP and ESA deadlines are pretty far off; there aren't a lot of good homes for algorithmic papers until then. (STOC/FOCS may not be appropriate; other conferences and workshops have, I think, weaker reputations that may make them less desirable, especially for up-and-coming students and younger faculty.) It seems like there's a hole in our schedule. Rather than fill it with yet another conference, wouldn't the community be better off accepting more?
Is that a good number? Too many? Too few?
I admit, I have trouble believing that there weren't at least 40, 50, maybe 100 of those rejected submitted papers that were of sufficient quality that it would have been just fine to have them in. I could be wrong -- I wasn't on the committee -- but I'd guess there was more good stuff out there.
For those papers that were rejected, where will they go? ICALP and ESA deadlines are pretty far off; there aren't a lot of good homes for algorithmic papers until then. (STOC/FOCS may not be appropriate; other conferences and workshops have, I think, weaker reputations that may make them less desirable, especially for up-and-coming students and younger faculty.) It seems like there's a hole in our schedule. Rather than fill it with yet another conference, wouldn't the community be better off accepting more?
Tuesday, September 13, 2011
Rabin's Birthday Celebration
While I was not blogging, we spent the few days before the semester started with an 80th birthday workshop for Michael Rabin. Impressively, we were able to pull it off despite the best efforts of Hurricane Irene, thanks to the many speakers who made an extra effort to get there, well beyond the call of duty. Because some speakers couldn't make it (flight cancellations), and we were worried about storm cleanup, we postponed the start until Monday afternoon, but other than that, it went fantastically well. (A credit to the organization of Les Valiant!)
Richard Lipton described it all in this blog post, so I don't have to. (The only negative thing in his post is that he refers to me as Mitz -- clearly because it's the easiest way of distinguishing me from the guest of honor, he doesn't call me that regularly -- which feels strange to me as I haven't been called that regularly since middle school.)
If any coding theory people are reading this, I thought I'd point out that the slides for my talk (as well as the slides for many of the other talks), which was on coding theory, are available here. In particular my talk is about how Michael Rabin's JACM paper on the Information Dispersal Algorithm was remarkably prescient, setting up some basic ideas and foundations for both the later work in LDPC codes and network coding. While the paper is far from unknown (Google scholar has it at well over 1000 citations), I'm not sure how widely appreciated the paper is in the coding theory circles; it was a pleasure for me to go back and reread it with new eyes to prepare for this talk.
Richard Lipton described it all in this blog post, so I don't have to. (The only negative thing in his post is that he refers to me as Mitz -- clearly because it's the easiest way of distinguishing me from the guest of honor, he doesn't call me that regularly -- which feels strange to me as I haven't been called that regularly since middle school.)
If any coding theory people are reading this, I thought I'd point out that the slides for my talk (as well as the slides for many of the other talks), which was on coding theory, are available here. In particular my talk is about how Michael Rabin's JACM paper on the Information Dispersal Algorithm was remarkably prescient, setting up some basic ideas and foundations for both the later work in LDPC codes and network coding. While the paper is far from unknown (Google scholar has it at well over 1000 citations), I'm not sure how widely appreciated the paper is in the coding theory circles; it was a pleasure for me to go back and reread it with new eyes to prepare for this talk.
Monday, September 12, 2011
Blogging Again?
My thoughts that I would blog more over the summer, during academic "down time", turned out more of a fiction than I would have thought. The summer proved remarkably busy, with plenty of research, administration, consulting (the economy must be coming back?), and, more enjoyably, time with the kids. The blog was low priority.
With the school year starting, I actually feel I have things to say, so we'll try again.
Classes have started, and Harvard's continuing growth in CS, well, it continues. Our intro CS course ended up with about 500 students last year; this year, we've currently got 650 enrolled. Our 2nd semester programming course designed primarily for majors has gone from 70 to 110 enrolled. Most importantly for me, our intro theory course (the Turing machine class) went from about 55 to 75. My algorithms and data structures class tends to be just a few less than that 2nd semester, so I'll have to plan for a jump up. (My biggest year was 90, back in the (last) bubble days; I'm not sure we'll ever get back there, as students have more class choices now.)
Really, we're trying to put more resources early in the pipeline to attract students to the intro course -- and we seem to be in a healthy positive feedback loop, which is (over time) pushing all the numbers up in later courses. Apparently tech is popular again.
I'm teaching randomized algorithms and probabilistic analysis, a graduate course that splits 1/2 grad and 1/2 undergrad. Currently I have 23 students, which is a nice and healthy but not earth-shattering number.
It's exciting to come back and see these numbers continuing to go up. No wonder we're #2 on Newsweek's Schools for Computer Geeks. (And no, we don't take that seriously.) Besides giving some evidence that we're on the right track, it should make the case for hiring more in CS easier to make.
With the school year starting, I actually feel I have things to say, so we'll try again.
Classes have started, and Harvard's continuing growth in CS, well, it continues. Our intro CS course ended up with about 500 students last year; this year, we've currently got 650 enrolled. Our 2nd semester programming course designed primarily for majors has gone from 70 to 110 enrolled. Most importantly for me, our intro theory course (the Turing machine class) went from about 55 to 75. My algorithms and data structures class tends to be just a few less than that 2nd semester, so I'll have to plan for a jump up. (My biggest year was 90, back in the (last) bubble days; I'm not sure we'll ever get back there, as students have more class choices now.)
Really, we're trying to put more resources early in the pipeline to attract students to the intro course -- and we seem to be in a healthy positive feedback loop, which is (over time) pushing all the numbers up in later courses. Apparently tech is popular again.
I'm teaching randomized algorithms and probabilistic analysis, a graduate course that splits 1/2 grad and 1/2 undergrad. Currently I have 23 students, which is a nice and healthy but not earth-shattering number.
It's exciting to come back and see these numbers continuing to go up. No wonder we're #2 on Newsweek's Schools for Computer Geeks. (And no, we don't take that seriously.) Besides giving some evidence that we're on the right track, it should make the case for hiring more in CS easier to make.
Subscribe to:
Posts (Atom)