There are many things I'm thankful for this year. Perhaps most notably, the new year marks the halfway point of my 3-year stint as "Area Dean for Computer Science". Not that I'm counting. I'm very thankful for that.
Strangely, though, despite the additional job, looking back on the year, it's been very enjoyable, research-wise. That's not due to me. So, importantly, it's time to thank some people.
First off, I thank my students. Justin, Zhenming, and (now-ex-student-but-collaborator-who-I-still-call-student) Giorgos are all doing really interesting and exciting things. They've been teaching me all sorts of new stuff, and have put up with my increasingly random availability as various non-essential Area Dean type meetings jump in the way. Having multiple students all making great progress on entirely different areas makes the job really, really fun.
Thanks to Michael Goodrich, who called me up about two years ago (has it been that long? I had to go back and check) and wondered if I could help him on a project where he wanted to use cuckoo hashing. And since then, he's continued to keep me busy research-wise, as we've jumped from trying to understand how to use cuckoo hashing in Oblivious RAM simulations to other practical uses of cuckoo hashing as well as other algorithmic and data structures problems. He's an idea factory, and I get to come along for the ride.
Similar thanks to George Varghese, who regularly provokes me into networking research. I always have to listen closely when talking to George because there's usually some insight he has, often I think not yet fully formed in his own mind yet, that when you see it will leave you with an AHA moment. (Sometimes, then, George mistakenly attributes the idea to me, even though my understanding comes from listening to him.) Also, both Michael and George have been really, really patient with me this year.
I of course thank the MIC/MINE group, who I've already been thanking all week. And John Byers, who has worked with me on more papers than anyone now, and is still willing to keep coming back.
I'd like to thank all the CS faculty at Harvard. When I travel around, and people ask me if it's hard being Area Dean, and how much do I have to do, I have to explain that it's not really that hard. There's some basic handling of paperwork and e-mail. Other than that, as a group we have lunch on Fridays to talk about things we have to do. I then sometimes have to ask people to do things so things actually get done (because I can't do everything myself). Then people do them, and as a group we're all very happy. When I try to explain this, sometimes other people look at me like I'm totally insane, which I've come to interpret as meaning that this is not the way it works everywhere. I've got a great group of colleagues, so I can still sneak in some research time here and there.
I also tremendously thank Tristen Dixey, the Area Administrator for CS and EE. She's the one that actually runs the place (thank goodness). Seriously, I'd be lost without Tristen. Many are the requests sent to me where my response is, "Let me check with Tristen on that." Because she knows what to do.
Thanks to all my other co-authors, and anyone else I'm forgetting to thank.
Finally, I thank the NSF, as well as currently Google and Yahoo, for sponsoring my research. I especially have to thank the NSF; while I can't say I think they're perfect, I can say that I think they're wonderful. They've funded me as a faculty member for over a decade now, and my students and I couldn't do the research I like to do without them.
I also, more privately, thank my family, for putting up with my working habits.
Happy new year to all.
(Just 18 more months...)
Friday, December 30, 2011
Thursday, December 29, 2011
Cross-Cultural Learning Curve: Sending a Paper to Science
We decided to submit our paper on MIC and MINE to Science it's a venue that my co-authors were familiar with and very interested in applying to. I was happy to go along. Moreover, it seemed like the right venue, as we wanted to reach a large audience of people who might be able to use the approach.
Sending a paper into Science feels very different than sending to a FOCS/STOC/SODA or SIGCOMM conference, or to a CS journal. I think there are many reasons for this. (And I'm trying not to offer judgment, one way or another -- but rather to describe the experience.)
1. There's a feeling that there's not really a second shot. If you submit a paper to a major CS conference, and it doesn't get in, you revise as needed and can try for the next one. (Some papers get submitted 3, 4, or more times before getting in.) For a journal like Science, they'll only review a small fraction of submitted papers, and if your paper doesn't make it in, you're not going to get a second shot there; you'll have to find another, arguably less desirable venue. (SIGCOMM can feel more that way, more than FOCS/STOC, but definitely not to the same extreme.)
2. Perhaps correspondingly, there's a greater focus on polish of the final form before submission. The article should be ready for publication in the journal, which has a high standard in terms of the appearance of the articles, so there's a sense that it should look good. This means much more time is spent on writing (and re-writing, and re-writing), on trying to figure what the perfect graphic is, on making that graphic look awesome, and other aspects of the presentation. On the whole, CS papers are, shall we say, much less presentation focused.
3. The paper will (likely) be read by a much broader (and larger) audience. This again changes how one thinks about presentation.
4. For many fields, a Science article is extremely important, much more valued for a student author than even a FOCS/STOC/SIGCOMM paper. (I realize that, in computer science, venues like Science and Nature have not historically been given an especially high importance.)
5. Journals like Science have very strict rules regarding various things. For example, we were not supposed to publish the work in another venue (like a conference) before hand. Once the paper was accepted, there was an "embargo" -- we weren't supposed to talk about it before publication without permission, and we could not announce the paper had been accepted. In CS, we have the arxiv and other online repositories that are used widely by theoreticians; even in areas where double-blind conference submissions are the norm, such rules are not taken anywhere nearly as seriously as by Science, as far as I can tell.
I've also been truly surprised by the amount of reaction the paper has generated. Sure, I had been told that getting a paper in Science is a big deal, but it's another thing to sort of see it in action. (I haven't seen this big a reaction since -- well, since Giorgos, John, and I put the Groupon paper up on the arxiv. But that was very unusual, and this reaction has I think been bigger.) There's definitely a human interest angle that is a part of that -- brothers working together on science makes a more readable news story -- but also there was much more effort behind the scenes. There's the sense that an article in Science is really a big chance to get your work noticed, so you prepare for that as well.
If I had to describe it in one word, I'd say publishing in Science feels much more "intense" than usual CS publications. The competitive aspect -- that some people in CS feel is very important (the "conferences are quality control" argument) and others do not -- feels like it's taken one level up here. Maybe the stakes are bigger. As an outsider, I was both amazed by and bemused by some aspects of the process. Even having been through it, I don't feel qualified to offer a grounded opinion as to which is better for the scientific enterprise, though I certainly feel it's an interesting issue to discuss.
Sending a paper into Science feels very different than sending to a FOCS/STOC/SODA or SIGCOMM conference, or to a CS journal. I think there are many reasons for this. (And I'm trying not to offer judgment, one way or another -- but rather to describe the experience.)
1. There's a feeling that there's not really a second shot. If you submit a paper to a major CS conference, and it doesn't get in, you revise as needed and can try for the next one. (Some papers get submitted 3, 4, or more times before getting in.) For a journal like Science, they'll only review a small fraction of submitted papers, and if your paper doesn't make it in, you're not going to get a second shot there; you'll have to find another, arguably less desirable venue. (SIGCOMM can feel more that way, more than FOCS/STOC, but definitely not to the same extreme.)
2. Perhaps correspondingly, there's a greater focus on polish of the final form before submission. The article should be ready for publication in the journal, which has a high standard in terms of the appearance of the articles, so there's a sense that it should look good. This means much more time is spent on writing (and re-writing, and re-writing), on trying to figure what the perfect graphic is, on making that graphic look awesome, and other aspects of the presentation. On the whole, CS papers are, shall we say, much less presentation focused.
3. The paper will (likely) be read by a much broader (and larger) audience. This again changes how one thinks about presentation.
4. For many fields, a Science article is extremely important, much more valued for a student author than even a FOCS/STOC/SIGCOMM paper. (I realize that, in computer science, venues like Science and Nature have not historically been given an especially high importance.)
5. Journals like Science have very strict rules regarding various things. For example, we were not supposed to publish the work in another venue (like a conference) before hand. Once the paper was accepted, there was an "embargo" -- we weren't supposed to talk about it before publication without permission, and we could not announce the paper had been accepted. In CS, we have the arxiv and other online repositories that are used widely by theoreticians; even in areas where double-blind conference submissions are the norm, such rules are not taken anywhere nearly as seriously as by Science, as far as I can tell.
I've also been truly surprised by the amount of reaction the paper has generated. Sure, I had been told that getting a paper in Science is a big deal, but it's another thing to sort of see it in action. (I haven't seen this big a reaction since -- well, since Giorgos, John, and I put the Groupon paper up on the arxiv. But that was very unusual, and this reaction has I think been bigger.) There's definitely a human interest angle that is a part of that -- brothers working together on science makes a more readable news story -- but also there was much more effort behind the scenes. There's the sense that an article in Science is really a big chance to get your work noticed, so you prepare for that as well.
If I had to describe it in one word, I'd say publishing in Science feels much more "intense" than usual CS publications. The competitive aspect -- that some people in CS feel is very important (the "conferences are quality control" argument) and others do not -- feels like it's taken one level up here. Maybe the stakes are bigger. As an outsider, I was both amazed by and bemused by some aspects of the process. Even having been through it, I don't feel qualified to offer a grounded opinion as to which is better for the scientific enterprise, though I certainly feel it's an interesting issue to discuss.
Tuesday, December 27, 2011
Some of The Fun of Collaborating...The Other People
One of the things I enjoy most about working in algorithms is the breadth of work I get to do. And while I've worked on a variety of things, almost all have been squarely in Computer Science. (If one counts information theory as EE then perhaps not, but CS/EE at the level I work on them are nearly equivalent from my point of view.) But at Harvard there are plenty of opportunities to work with people outside of computer science, and my work on MIC and MINE was my biggest cross-cultural collaboration at Harvard. In particular, the other co-primary-advisor on the work was Pardis Sabeti, who works in systems biology at Harvard -- here's the link to her lab page.
Pardis is no stranger to mathematical thinking -- some of her work that she's most well known for is in designing statistical tests to detect mutations at the very short time scale of humans over the last 10,000 years, with the goal being to identify parts of the genome that have undergone natural selection in response to diseases. So while my take was a bit more CS/math focused (what can we prove? how fast/complex is our algorithm?) and hers what a bit more biology/statistics focused (what is this telling us about the data? what data sets can we apply this too?) the lines were pretty blurry. But it did mean I got to pick up a little biology and public health on the way. Who knew that natural selection could be so readily found in humans? Or that the graph of weight vs. income by country has some really unusual characteristics (weight goes up with national income up to some point, but then goes down again; the outliers are the US, and Pacific island nations)? And that you can find genes that are strongly tied to susceptibility to certain viral diseases?
I must admit, it is a bit intimidating when talking to a colleague about your other projects, and I'm explaining cuckoo hashing and Groupon, while she's discussing flying off for the Nth time this year to Africa for her project on how genes are changing in response to Ebola and Lassa viruses. But it's just encouraged me to keep looking for these sorts of broadening opportunities. Maybe someday I'll find a project I too can work on that will help us understand viruses and diseases. (Hint, Pardis, hint!)
The primary student collaborators were David and Yakir Reshef. David was a student at MIT when he took my graduate class Algorithms at the End of the Wire, which covers information theory as one of the units. He had already been working with Pardis on data mining problems and ended up working on an early version of MINE as his project for the class. I told him he should continue the project and I'd be happy to help out. It's always nice when class projects turn into papers -- something I try to encourage. This one turned out better than most.
David continued working with his brother Yakir (along with me and Pardis). David and Yakir are both cross-cultural people; Yakir is currently a Fulbright scholar in the Department of Applied Math and Computer Science at Weizmann, after getting his BA in math at Harvard -- but is currently applying to MD/PhD programs. David is getting his MD/PhD here at Harvard-MIT Health Sciences and Technology Program, after having spent the last few years at Oxford on a Marshall doing graduate work in statistics. So between them they definitely provided plenty of glue between me and Pardis. Both of them pushed me to learn a bunch of statistics along the way. I'm not sure I was the best student, but I read a bunch of statistics papers for this work, to know what work was out there on these sorts of problems.
Others also came into the project, the most notable for me being Hilary Finucane -- who I wrote multiple papers with when she was a Harvard undergrad, and who was simultaneously busy obtaining her MSc in theoretical computer science at Weizmann. And who is now engaged to Yakir (they were a couple together back at Harvard) . With two brothers and a fiancee in the mix, the paper was a friendly, family-oriented affair. I also got to meet and work with Eric Lander, who was one of the leaders in sequencing the human genome, and quickly found out how amazing he is.
Like many of my collaborations these days, the work would have been impossible without Skype -- at various points on the project, we had to set up meetings between Boston, Oxford, and Israel, which generally meant at least one group was awake at an unusual hour. But that sort of group commitment helped keep the energy up for the project over the long haul.
The work on MIC and MINE was a multi-year project, and was definitely more effort than most papers I am involved with. On the other hand, because it was a great team to work with, I enjoyed the process. I got to work with a bunch of people with different backgrounds and experiences, all of whom are immensely talented; they pushed me to learn new things so I could keep up. I'm glad the work ended up being published in a prestigious journal -- especially because the students deserve the payoff. But even if it hadn't, it would have been a successful collaboration for me.
Pardis is no stranger to mathematical thinking -- some of her work that she's most well known for is in designing statistical tests to detect mutations at the very short time scale of humans over the last 10,000 years, with the goal being to identify parts of the genome that have undergone natural selection in response to diseases. So while my take was a bit more CS/math focused (what can we prove? how fast/complex is our algorithm?) and hers what a bit more biology/statistics focused (what is this telling us about the data? what data sets can we apply this too?) the lines were pretty blurry. But it did mean I got to pick up a little biology and public health on the way. Who knew that natural selection could be so readily found in humans? Or that the graph of weight vs. income by country has some really unusual characteristics (weight goes up with national income up to some point, but then goes down again; the outliers are the US, and Pacific island nations)? And that you can find genes that are strongly tied to susceptibility to certain viral diseases?
I must admit, it is a bit intimidating when talking to a colleague about your other projects, and I'm explaining cuckoo hashing and Groupon, while she's discussing flying off for the Nth time this year to Africa for her project on how genes are changing in response to Ebola and Lassa viruses. But it's just encouraged me to keep looking for these sorts of broadening opportunities. Maybe someday I'll find a project I too can work on that will help us understand viruses and diseases. (Hint, Pardis, hint!)
The primary student collaborators were David and Yakir Reshef. David was a student at MIT when he took my graduate class Algorithms at the End of the Wire, which covers information theory as one of the units. He had already been working with Pardis on data mining problems and ended up working on an early version of MINE as his project for the class. I told him he should continue the project and I'd be happy to help out. It's always nice when class projects turn into papers -- something I try to encourage. This one turned out better than most.
David continued working with his brother Yakir (along with me and Pardis). David and Yakir are both cross-cultural people; Yakir is currently a Fulbright scholar in the Department of Applied Math and Computer Science at Weizmann, after getting his BA in math at Harvard -- but is currently applying to MD/PhD programs. David is getting his MD/PhD here at Harvard-MIT Health Sciences and Technology Program, after having spent the last few years at Oxford on a Marshall doing graduate work in statistics. So between them they definitely provided plenty of glue between me and Pardis. Both of them pushed me to learn a bunch of statistics along the way. I'm not sure I was the best student, but I read a bunch of statistics papers for this work, to know what work was out there on these sorts of problems.
Others also came into the project, the most notable for me being Hilary Finucane -- who I wrote multiple papers with when she was a Harvard undergrad, and who was simultaneously busy obtaining her MSc in theoretical computer science at Weizmann. And who is now engaged to Yakir (they were a couple together back at Harvard) . With two brothers and a fiancee in the mix, the paper was a friendly, family-oriented affair. I also got to meet and work with Eric Lander, who was one of the leaders in sequencing the human genome, and quickly found out how amazing he is.
Like many of my collaborations these days, the work would have been impossible without Skype -- at various points on the project, we had to set up meetings between Boston, Oxford, and Israel, which generally meant at least one group was awake at an unusual hour. But that sort of group commitment helped keep the energy up for the project over the long haul.
The work on MIC and MINE was a multi-year project, and was definitely more effort than most papers I am involved with. On the other hand, because it was a great team to work with, I enjoyed the process. I got to work with a bunch of people with different backgrounds and experiences, all of whom are immensely talented; they pushed me to learn new things so I could keep up. I'm glad the work ended up being published in a prestigious journal -- especially because the students deserve the payoff. But even if it hadn't, it would have been a successful collaboration for me.
Monday, December 26, 2011
Wasted Hour(s)
Last night I was running some code for a queuing simulation related to some research I'm doing. This is the Nth time I've used this code; I wrote up the basic simulator back in grad school for some of my thesis work (on the power of two choices), and every once in a couple years or so, some project pops up where what I want is some variant of it. So I copy whatever version is lying around, tweak it for the new problem, and off I go.
Today when I was putting together the table the numbers just didn't look right to me. I re-checked the theory and it was clearly telling me that output X should be less than output Y, but that wasn't how the numbers were coming out. Something was wrong somewhere.
After staring at the code a while, and running a few unhelpful tests, I decided to go back to square 1, and just run the code in the "old" configuration, where I knew exactly what I should get. And I didn't get it.
That helped tell me where to look. Sure enough, a couple minutes later, I found the "bad" line of code; last project, I must have wanted to look at queues with constant service times instead of exponential service times, and I had just changed that line; now I needed it changed back. And all is well with the world again.
I'm sure there are some lessons in there somewhere -- about documenting code, about setting things up as parameters instead of hard-wiring things in, all that good stuff one should do but doesn't always. It catches up to you sooner or later. Meanwhile, the code is back to running, and in about 24 hours I'll hopefully have the table I need.
Today when I was putting together the table the numbers just didn't look right to me. I re-checked the theory and it was clearly telling me that output X should be less than output Y, but that wasn't how the numbers were coming out. Something was wrong somewhere.
After staring at the code a while, and running a few unhelpful tests, I decided to go back to square 1, and just run the code in the "old" configuration, where I knew exactly what I should get. And I didn't get it.
That helped tell me where to look. Sure enough, a couple minutes later, I found the "bad" line of code; last project, I must have wanted to look at queues with constant service times instead of exponential service times, and I had just changed that line; now I needed it changed back. And all is well with the world again.
I'm sure there are some lessons in there somewhere -- about documenting code, about setting things up as parameters instead of hard-wiring things in, all that good stuff one should do but doesn't always. It catches up to you sooner or later. Meanwhile, the code is back to running, and in about 24 hours I'll hopefully have the table I need.
Thursday, December 22, 2011
MIC and MINE, a short description
I thought I should give a brief description of MIC and MINE, the topic of our Science paper. Although you're probably better off, if you're interested, looking at our website, http://www.exploredata.net/. Not only does it have a brief description of the algorithm, but now we have a link that gives access to the paper (if you couldn't access it previously) available on this page, thanks to the people at Science.
Our starting point was figuring out what to do with large, multidimensional data sets. If you're given a bunch of data, how do you start to figure out what might be interesting? A natural approach is to calculate some measure on each pair of variables which serves as a proxy for how interesting they are -- where interesting, to us, means that the variables appear dependent in some way. Once you have this, you can pull out the top-scoring pairs and take a closer look.
What properties would we like our measure to have?
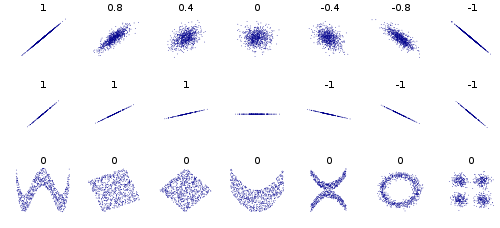
First, we would like it to be general, in the sense that it should pick up as diverse a collection of possible associations between variables as possible. The well-known Pearson correlation coefficient, for example, does not have this property -- as you can see from this Wikipedia picture

it's great at picking up linear relationships, but other relationships (periodic sine waves, parabolas, exponential functions, circular associations) it's not so good at.
Second, we would like it to be what we call equitable. By this we mean that scores should degrade with noise at (roughly) the same rate. If you start with a line and start with a sine wave, and add an equivalent amount of noise to both of them in the same way, the resulting scores should be about the same; otherwise the method would give preference to some types of relationships over others.
I should point out that the goal behind these properties is to allow exploration -- the point is you don't know what sort of patterns in the data you should be looking for. If you do know, you're probably better off using a specific tests. If you're looking for linear relationships, Pearson is great -- and there are a large variety of powerful tests that have been developed for specific types of relationships over the years.
Our suggested measure, MIC (maximal information coefficient), is based on mutual information, but is different from it. Our intuition is that if a relationship exists between two variables, then a grid can be drawn on the scatterplot that partitions the data in a way that corresponds to that relationship. Suppose we have a grid, with x rows and y columns; then this grid induces a probability distribution, where the probability associated with a box on the grid is proportional to the number of data points it contains. Let I_G be the mutual information of the grid. We aim to maximize I_G/ log min(x,y) -- this is the MIC score. (We bound x, y values to avoid trivial cases like every point having its own box; see the paper for more details.) MIC values are between 0 and 1, and we can approximately compute MIC values heuristically. Our work shows via a mix of proofs and experiments that MIC appears to have the properties of generality and equitability we desire.
Based on the approach we use to find MIC, we suggest several other possible useful measures, and we refer to the collection as MINE (maximal information-based nonparametric exploration) statistics. For example, MIC - Pearson^2 turns out to be a useful measure for specifically finding nonlinear relationships. When MIC is high (close to 1) and Pearson is low (close to 0), there is a relationship that MIC has found but it is not a linear one; for linear patterns, both MIC and Pearson are high, and so this measure is close to 0. Other measures we have measure things like deviations from monotonicity -- useful for finding periodic relationships.
Should MIC/MINE prove useful, I believe there's lots of theoretical questions left to consider. The approach is currently essentially heuristic, although we do prove a fair number of things about it. Proving more about its properties would be useful, as well as improving the complexity to compute the relevant measures.
Next up: more about the experience of working on this project.
Our starting point was figuring out what to do with large, multidimensional data sets. If you're given a bunch of data, how do you start to figure out what might be interesting? A natural approach is to calculate some measure on each pair of variables which serves as a proxy for how interesting they are -- where interesting, to us, means that the variables appear dependent in some way. Once you have this, you can pull out the top-scoring pairs and take a closer look.
What properties would we like our measure to have?
First, we would like it to be general, in the sense that it should pick up as diverse a collection of possible associations between variables as possible. The well-known Pearson correlation coefficient, for example, does not have this property -- as you can see from this Wikipedia picture
{kind=link}
it's great at picking up linear relationships, but other relationships (periodic sine waves, parabolas, exponential functions, circular associations) it's not so good at.
Second, we would like it to be what we call equitable. By this we mean that scores should degrade with noise at (roughly) the same rate. If you start with a line and start with a sine wave, and add an equivalent amount of noise to both of them in the same way, the resulting scores should be about the same; otherwise the method would give preference to some types of relationships over others.
I should point out that the goal behind these properties is to allow exploration -- the point is you don't know what sort of patterns in the data you should be looking for. If you do know, you're probably better off using a specific tests. If you're looking for linear relationships, Pearson is great -- and there are a large variety of powerful tests that have been developed for specific types of relationships over the years.
Our suggested measure, MIC (maximal information coefficient), is based on mutual information, but is different from it. Our intuition is that if a relationship exists between two variables, then a grid can be drawn on the scatterplot that partitions the data in a way that corresponds to that relationship. Suppose we have a grid, with x rows and y columns; then this grid induces a probability distribution, where the probability associated with a box on the grid is proportional to the number of data points it contains. Let I_G be the mutual information of the grid. We aim to maximize I_G/ log min(x,y) -- this is the MIC score. (We bound x, y values to avoid trivial cases like every point having its own box; see the paper for more details.) MIC values are between 0 and 1, and we can approximately compute MIC values heuristically. Our work shows via a mix of proofs and experiments that MIC appears to have the properties of generality and equitability we desire.
Based on the approach we use to find MIC, we suggest several other possible useful measures, and we refer to the collection as MINE (maximal information-based nonparametric exploration) statistics. For example, MIC - Pearson^2 turns out to be a useful measure for specifically finding nonlinear relationships. When MIC is high (close to 1) and Pearson is low (close to 0), there is a relationship that MIC has found but it is not a linear one; for linear patterns, both MIC and Pearson are high, and so this measure is close to 0. Other measures we have measure things like deviations from monotonicity -- useful for finding periodic relationships.
Should MIC/MINE prove useful, I believe there's lots of theoretical questions left to consider. The approach is currently essentially heuristic, although we do prove a fair number of things about it. Proving more about its properties would be useful, as well as improving the complexity to compute the relevant measures.
Next up: more about the experience of working on this project.
Sunday, December 18, 2011
Congratulations to Hanspeter Pfister
Despite our really very good track record for the last decade or so, there are some people out there who remain under the misimpression that it's impossible to get tenure at Harvard.
So I'm very happy to announce that Hanspeter Pfister has achieved the impossible, and is now a tenured Harvard Professor.
Hanspeter works in graphics and visualization, doing the usual sort of things like replacing your face in videos and designing 3-d printers that work like a Star Trek replicator. But he has also developed a large number of collaborations with domain scientists, finding interesting and important visualization problems in things like diagnosing heart disease and mapping the brain.
We're all happy he'll be staying around. Hooray for Hanspeter!
So I'm very happy to announce that Hanspeter Pfister has achieved the impossible, and is now a tenured Harvard Professor.
Hanspeter works in graphics and visualization, doing the usual sort of things like replacing your face in videos and designing 3-d printers that work like a Star Trek replicator. But he has also developed a large number of collaborations with domain scientists, finding interesting and important visualization problems in things like diagnosing heart disease and mapping the brain.
We're all happy he'll be staying around. Hooray for Hanspeter!
Friday, December 16, 2011
This Week, I Am A Scientist
This week, I am a scientist; I know this, because I have an article in Science.
It's nice to have something to point to that my parents can understand. I don't mean they'll understand the paper, but they'll understand that getting a paper in Science is important, more so than my papers that appear other places. And because they're probably reading this, I will also point them to the Globe article appearing today about the work, even though the article rightly focuses on the cool and unusual fact that the lead authors are two brothers, David and Yakir Reshef.
I had been planning to write one or more posts about the paper -- both the technical stuff and the great fun I've been having working with David, Yakir, my long-time colleague Hilary Finucane, the truly amazing systems biology professor Pardis Sabeti, and others on this project. (See Pardis's Wikipedia page or this site to see how Pardis rocks!) But between Science's "news embargo" policies and my own end-of-semester busy-ness, I blew it. I'll try to have them out next week. But for now, for those of you who might be interested, here's the link to the project web page, and here's the abstract:
It's nice to have something to point to that my parents can understand. I don't mean they'll understand the paper, but they'll understand that getting a paper in Science is important, more so than my papers that appear other places. And because they're probably reading this, I will also point them to the Globe article appearing today about the work, even though the article rightly focuses on the cool and unusual fact that the lead authors are two brothers, David and Yakir Reshef.
I had been planning to write one or more posts about the paper -- both the technical stuff and the great fun I've been having working with David, Yakir, my long-time colleague Hilary Finucane, the truly amazing systems biology professor Pardis Sabeti, and others on this project. (See Pardis's Wikipedia page or this site to see how Pardis rocks!) But between Science's "news embargo" policies and my own end-of-semester busy-ness, I blew it. I'll try to have them out next week. But for now, for those of you who might be interested, here's the link to the project web page, and here's the abstract:
Detecting Novel Associations in Large Data Sets
Abstract: Identifying interesting relationships between pairs of variables in large data sets is increasingly important. Here, we present a measure of dependence for two-variable relationships: the maximal information coefficient (MIC). MIC captures a wide range of associations both functional and not, and for functional relationships provides a score that roughly equals the coefficient of determination (R2) of the data relative to the regression function. MIC belongs to a larger class of maximal information-based nonparametric exploration (MINE) statistics for identifying and classifying relationships. We apply MIC and MINE to data sets in global health, gene expression, major-league baseball, and the human gut microbiota and identify known and novel relationships.Thursday, December 15, 2011
Consulting
As I've probably mentioned, I generally enjoy my consulting work. Besides the obvious remunerative aspects, consulting provides challenges, insights, and experiences that are quite different from academic work.
On the other hand, taking red-eyes and having to get up at 4 am for a 6 am flight to a meeting in another city -- both of which I had to do this week -- I could happily do without.
On the other hand, taking red-eyes and having to get up at 4 am for a 6 am flight to a meeting in another city -- both of which I had to do this week -- I could happily do without.
Wednesday, December 14, 2011
Grading
Some folks at the NSDI meeting were nice enough to say that it was nice that I was blogging again. Sadly, I've been under-the-gun busy for the last several weeks, but it was a reminder that I should be getting back to this now and again.
One thing that's taken my time the last week is grading. I was teaching my graduate course this semester, on randomized algorithms and probabilistic analysis, using my book as the base. Unfortunately, I teach this course at most every other year, which means it's hard if not impossible to find a suitable TA. (As for my own students, Zhenming is on an internship this semester; Justin's on fellowship and essentially required not to TA. Also, both have been extremely busy this semester doing really great work, so why would I want them to TA instead of doing their research now anyway?) So this year I didn't have one. Which means I graded things myself.
It's been a while since I've graded a whole course. I do grade exams (with the TAs) and one full assignment (myself) every year in my undergraduate class. But grading every week is really at least as bad as having to do homework every week. I'd say worse; very little interesting thinking involved, just a lot of reading, checking, and moving papers or files around in a time-consuming fashion. Somehow, though, I don't think the students sympathize.
I think I remember one graduate class in Berkeley where a student (or maybe a group of students) were required to take on the grading every assignment. I like that plan. In fact, right now I like any plan that doesn't involve me grading the next time I teach this class. One plan is of course no/minimal homework, or homework without grades. However, I do believe students learn by doing homework, and I've found that in most circumstances a grade is the motivator that makes them get the homework done, so I'll have to find a plan that involves grading somehow.
One thing that's taken my time the last week is grading. I was teaching my graduate course this semester, on randomized algorithms and probabilistic analysis, using my book as the base. Unfortunately, I teach this course at most every other year, which means it's hard if not impossible to find a suitable TA. (As for my own students, Zhenming is on an internship this semester; Justin's on fellowship and essentially required not to TA. Also, both have been extremely busy this semester doing really great work, so why would I want them to TA instead of doing their research now anyway?) So this year I didn't have one. Which means I graded things myself.
It's been a while since I've graded a whole course. I do grade exams (with the TAs) and one full assignment (myself) every year in my undergraduate class. But grading every week is really at least as bad as having to do homework every week. I'd say worse; very little interesting thinking involved, just a lot of reading, checking, and moving papers or files around in a time-consuming fashion. Somehow, though, I don't think the students sympathize.
I think I remember one graduate class in Berkeley where a student (or maybe a group of students) were required to take on the grading every assignment. I like that plan. In fact, right now I like any plan that doesn't involve me grading the next time I teach this class. One plan is of course no/minimal homework, or homework without grades. However, I do believe students learn by doing homework, and I've found that in most circumstances a grade is the motivator that makes them get the homework done, so I'll have to find a plan that involves grading somehow.
Tuesday, December 06, 2011
Plane Work
I dislike flying, but I have a few flights coming up.
I find that engaging in "real thinking" about problems while on a plane is generally beyond me. (I'm jealous of all of you that somehow manage this.) Similarly (or Even) writing code takes more focus than I can manage on a plane. But I do try to make my plane time useful.
Luckily, it's the end of the semester, so I think I'll be bringing the last homeworks and final exams to grade on board this time around.
Reviewing (conference) papers is something I manage on plane flights. I'm sure that says something about the level of my reviews. On the plane my goal isn't to read the paper in same depth that I'd read a paper I'm trying to understand for my research; it's to assign a score (sort) and write down useful comments. (Which, I guess, is my goal for conference reviews off the plane as well. And why I wouldn't do journal reviews on planes.) If you get a review you don't like, I suppose now you can always assume you can assign the blame to the fact that I was on a long plane flight. But I don't think I'll have any reviews this month.
Reviewing proposals is even better than reviewing conference papers on a plane. I often get foreign governments sending me proposals to review for them, and they often pay some nominal amount. If I know I have a flight coming up, I sometimes say yes. It makes me feel like I'm doing something useful on the flight, and even getting paid for it.
When all that fails, I try to read a mindless book. (It's always good to have one on hand for those interminable periods where your electronic devices must be turned off.) I slipped up and started reading V is for Vengeance at home. (I think I've read all the Kinsey Millhone books from A, but I started at around H, and can't recall if I found all the earlier ones. I wonder what she'll do after Z?) I've been saving Mockingjay
at home. (I think I've read all the Kinsey Millhone books from A, but I started at around H, and can't recall if I found all the earlier ones. I wonder what she'll do after Z?) I've been saving Mockingjay  for a plane flight though. (I try to read what my kids read. So I'm also quite familiar with Percy Jackson.) I've read most of Robert Parker's books
for a plane flight though. (I try to read what my kids read. So I'm also quite familiar with Percy Jackson.) I've read most of Robert Parker's books in the air.
in the air.
Finally, sometimes, I fall asleep. I've gotten reasonably good at sleeping on flights. Then I don't get the work I thought I'd get done on the plane done. But it definitely feels like a good use for the time.
I find that engaging in "real thinking" about problems while on a plane is generally beyond me. (I'm jealous of all of you that somehow manage this.) Similarly (or Even) writing code takes more focus than I can manage on a plane. But I do try to make my plane time useful.
Luckily, it's the end of the semester, so I think I'll be bringing the last homeworks and final exams to grade on board this time around.
Reviewing (conference) papers is something I manage on plane flights. I'm sure that says something about the level of my reviews. On the plane my goal isn't to read the paper in same depth that I'd read a paper I'm trying to understand for my research; it's to assign a score (sort) and write down useful comments. (Which, I guess, is my goal for conference reviews off the plane as well. And why I wouldn't do journal reviews on planes.) If you get a review you don't like, I suppose now you can always assume you can assign the blame to the fact that I was on a long plane flight. But I don't think I'll have any reviews this month.
Reviewing proposals is even better than reviewing conference papers on a plane. I often get foreign governments sending me proposals to review for them, and they often pay some nominal amount. If I know I have a flight coming up, I sometimes say yes. It makes me feel like I'm doing something useful on the flight, and even getting paid for it.
When all that fails, I try to read a mindless book. (It's always good to have one on hand for those interminable periods where your electronic devices must be turned off.) I slipped up and started reading V is for Vengeance
Finally, sometimes, I fall asleep. I've gotten reasonably good at sleeping on flights. Then I don't get the work I thought I'd get done on the plane done. But it definitely feels like a good use for the time.
Saturday, December 03, 2011
The End (of the Semester) is Nigh
If you've missed it (which probably means you're not a theorist and/or a blog-reader), you should check out the (entertaining) controversies of the last week or two, starting with Oded's guest post on the decline of intellectual values in Theoretical Computer Science, and then whether a lowering of the matrix multiplication exponent counts as a "breakthrough" (see follow-up blog posts here, here, and here).
I've enjoyed watching them develop, but have been happy to let them go on without putting a big target on my back. I've also been too busy getting through my last lectures, making up a final exam, trying to get some grant proposals ready on ridiculous deadlines, and dealing with administrative issues like prepping slides for an end-of-semester faculty retreat. Occasionally I try to fit in meeting with students and (last of all) working on research. I know the end of the semester is a mad rush for students, finishing projects and papers and getting ready for exams. Sadly, I feel the same way this year. Another week or two and it will be all over, and like the students I think I'm ready to let things go for a couple of weeks of holiday time.
But probably I'll stay up late after the kids are in bed and try to do some of that research stuff. There are some fun problems that have been waiting for attention most of the semester, and I'd like to see what happens if I'm finally able to give them some.
I've enjoyed watching them develop, but have been happy to let them go on without putting a big target on my back. I've also been too busy getting through my last lectures, making up a final exam, trying to get some grant proposals ready on ridiculous deadlines, and dealing with administrative issues like prepping slides for an end-of-semester faculty retreat. Occasionally I try to fit in meeting with students and (last of all) working on research. I know the end of the semester is a mad rush for students, finishing projects and papers and getting ready for exams. Sadly, I feel the same way this year. Another week or two and it will be all over, and like the students I think I'm ready to let things go for a couple of weeks of holiday time.
But probably I'll stay up late after the kids are in bed and try to do some of that research stuff. There are some fun problems that have been waiting for attention most of the semester, and I'd like to see what happens if I'm finally able to give them some.
Thursday, December 01, 2011
Letters of Recommendation Time. Ugh.
I don't mind writing letters of recommendation for students. It's part of the job. It's a good thing to do.
I just mind dealing with the new e-application sites. I'd rather hand my letter off to an admin and have them send it. The good old days...
To see what I'm talking about, I'm now a huge non-fan of Embark -- here's their "help page", which explains that I may have to wait 5+ minutes for my pdf to upload, without really explaining why
I just mind dealing with the new e-application sites. I'd rather hand my letter off to an admin and have them send it. The good old days...
To see what I'm talking about, I'm now a huge non-fan of Embark -- here's their "help page", which explains that I may have to wait 5+ minutes for my pdf to upload, without really explaining why
Subscribe to:
Posts (Atom)